A Challenger to the Tech Behind ChatGPT Has Arrived — Mamba-3 Uses Half the Memory and Runs Faster
Mamba-3, a new AI architecture challenging the Transformer technology at the core of ChatGPT, Claude, and Gemini, has been released as open source. It delivers the same performance with half the memory and 6% faster response times. Accepted at ICLR 2026.
ChatGPT, Claude, Gemini — virtually every AI service we use today is built on a single core technology called the Transformer. Invented by Google in 2017, it has been the engine of the AI revolution, but it has one critical weakness: the longer the text, the more memory and cost grow exponentially.
On March 17, a joint research team from Carnegie Mellon University (CMU), Princeton University, Together AI, and Cartesia AI released a new AI architecture called Mamba-3 as open source, taking direct aim at this problem. It cuts internal memory usage to half that of the previous Mamba-2, while achieving even faster response times than Transformers. The paper has been accepted at ICLR 2026, one of the most prestigious conferences in AI.

Transformer vs. Mamba — Think of It Like Swapping Out a Car Engine
Think of the Transformer as a car engine. Until now, every AI car has been running the same engine. It's incredibly powerful, but it has terrible fuel efficiency. The longer the text it processes, the more fuel (memory and electricity) it burns. Ask it to read an entire novel, and it needs more than four times the memory compared to reading half a novel.
Mamba solves this in a fundamentally different way. It uses a technology called SSM (State Space Model — a mathematical framework for how AI remembers and processes information), which keeps memory usage constant no matter how long the text gets. Whether it reads one novel or ten, it uses the same amount of memory.
Three Things Mamba-3 Changes
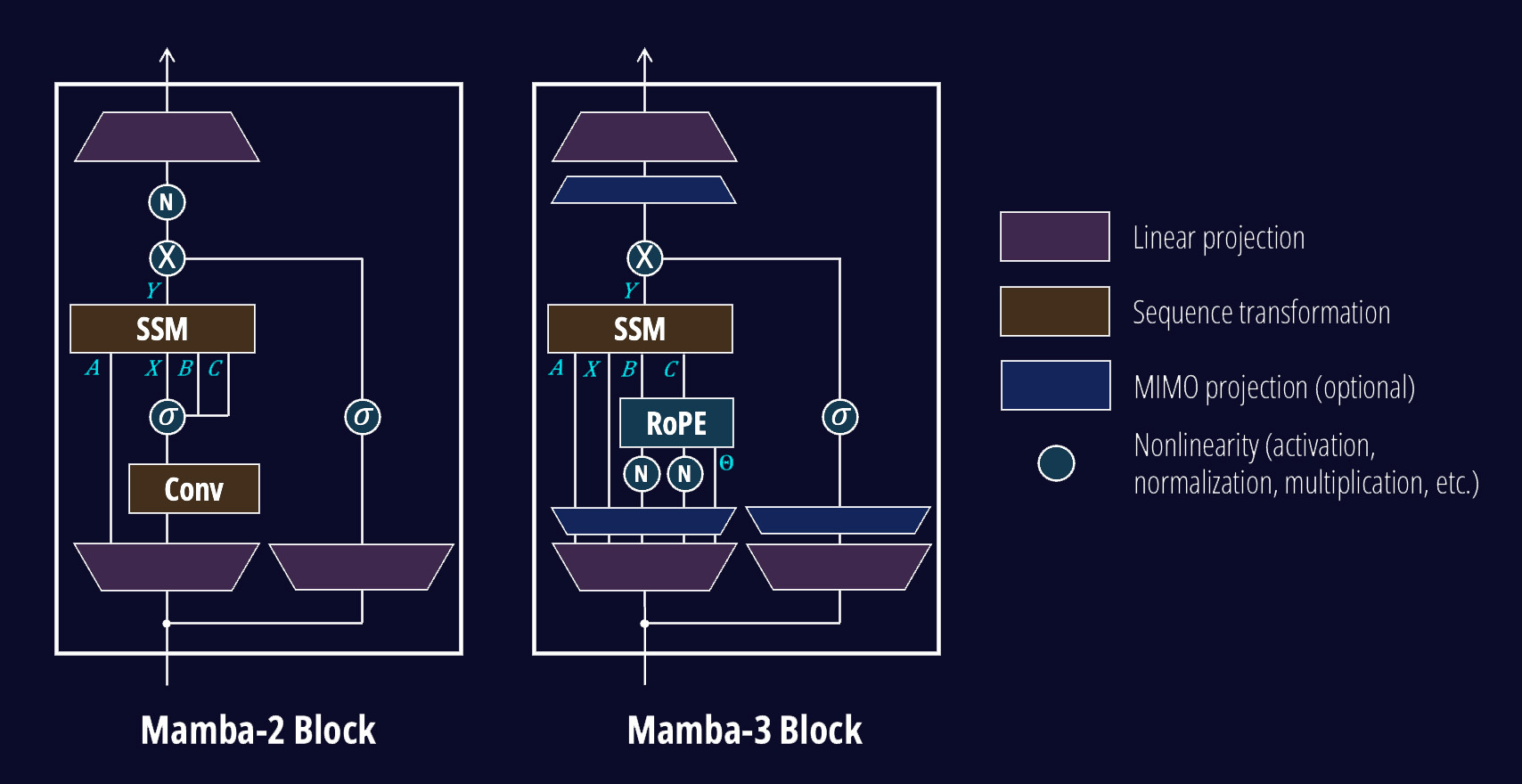
▲ Internal architecture comparison of Mamba-2 (left) and Mamba-3 (right). Mamba-3 removes the Conv (convolution) module and adds RoPE and MIMO for greater efficiency. (Source: Together AI)
Benchmarks — The Numbers Speak for Themselves
The research team compared performance at the 1.5 billion (1.5B) parameter scale on NVIDIA H100 GPUs. Parameters are a measure of an AI model's size — the more parameters, the more complex the tasks it can handle.
| Model | 512 Tokens | 4,096 Tokens |
|---|---|---|
| Mamba-3 (SISO) | 4.39s ✅ | 35.11s ✅ |
| Mamba-2 | 4.66s | 37.22s |
| Llama-3.2-1B (Transformer) | 4.45s | — |
Mamba-3 SISO recorded the fastest response times across all sequence lengths. At 512 tokens (roughly 400 words), it was 6% faster than Mamba-2, and at 4,096 tokens, it was 5.7% faster. Notably, it even outpaced Meta's Llama, a Transformer-based model.
The MIMO variant went further, boosting accuracy by an additional 1 to 1.8 percentage points — delivering more accurate answers at the same speed. And it does all this using only half the internal state size of Mamba-2.
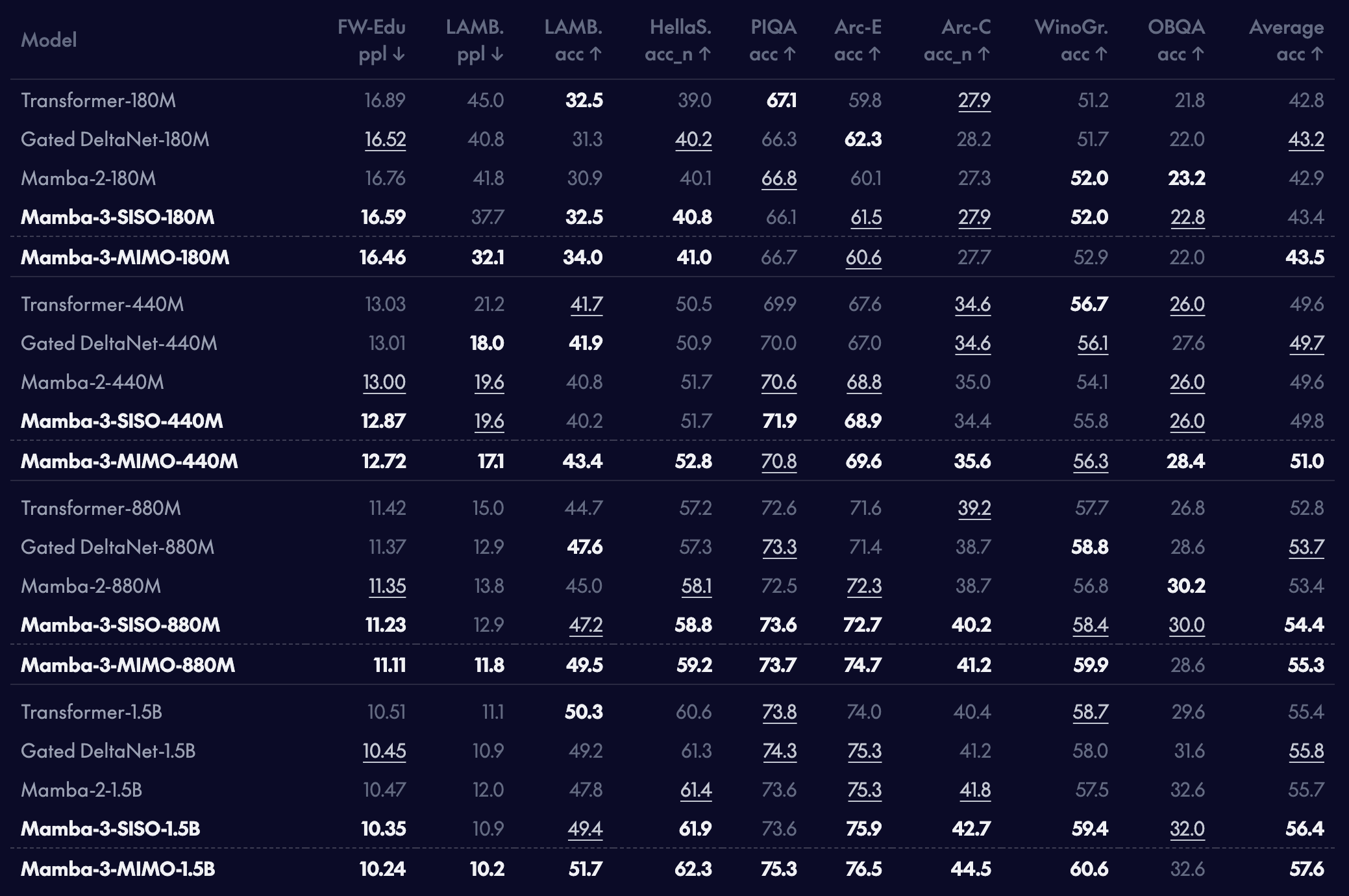
▲ Language modeling performance comparison between Mamba-3 and other models. Mamba-3 outperforms existing models across a range of benchmarks. (Source: Together AI)
AI Service Prices Could Drop Faster
Why does this matter? A significant portion of AI service costs comes from GPU memory. The reason ChatGPT charges more for processing long documents is precisely because Transformers consume so much memory. Right now, ChatGPT's input cost for one million tokens is around $2.50, and memory is a core driver of that cost.
If technology like Mamba-3 is adopted in commercial AI, the same GPU could serve twice as many users, meaning AI service prices could drop faster. Major AI companies like Google and Meta are already researching efficient architectures like Mamba.
It Won't Fully Replace Transformers — Not Yet
That said, Mamba-3 does have its weaknesses. When it comes to information retrieval (the task of pinpointing a specific passage accurately), Transformers still have the edge. The Transformer's "attention" mechanism (the feature that lets AI focus on the most relevant parts) excels at extracting specific content from massive documents.
The research team acknowledges this, stating that "the optimal future architecture will likely be a hybrid that combines Mamba's efficiency with the Transformer's powerful retrieval capabilities." In such a system, Mamba-3 would handle the scanning and processing, while Transformers would kick in when precise search is needed.
Developers Can Start Using It Right Now
Mamba-3 has been released under the Apache 2.0 license (fully free and open) and is available on GitHub (17,400 stars).
# Install after setting up PyTorch
pip install mamba-ssm --no-build-isolationPre-trained models are currently available for Mamba-1 (up to 2.8B) and Mamba-2 (up to 2.7B) on Hugging Face, and pre-trained Mamba-3 models are in preparation. An NVIDIA GPU with CUDA 11.6 or higher is required.
The significance of this research is clear: AI's core technology is no longer a one-horse race. Competition has arrived to challenge the Transformer's dominance, and the benefit will flow to every user in the form of faster and more affordable AI.
Related Content — Get Started with AI Using EasyClco | Free Learning Guide | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments