Flash-MoE runs a 397B AI model on a MacBook — at 5.5 tokens/sec
A new open-source engine streams a 397-billion-parameter AI model from SSD on a 48GB MacBook Pro, using just 5.5GB of RAM. Here's how it works.
A developer just proved you can run one of the largest open AI models on a laptop — no cloud required. Flash-MoE is a custom inference engine that runs Qwen3.5-397B (a 397-billion-parameter model) on a MacBook Pro with 48GB of RAM, achieving 5.5 tokens per second while using only 5.5GB of memory.
The entire 209GB model streams directly from the laptop's SSD through a hand-optimized Metal compute pipeline — no Python, no frameworks, just raw C, Objective-C, and Apple's Metal GPU shaders.
How a 209GB model fits in 5.5GB of RAM
The trick relies on how Mixture-of-Experts (MoE) models work. Think of MoE like a company with 128 specialists — for any given question, only 4 of them need to answer. Flash-MoE exploits this: instead of loading all 128 "expert" modules into memory, it streams just the 4 needed ones from the SSD on-the-fly.
Apple's M3 Max SSD reads at 17.5 GB/s — fast enough that loading 4 experts (~3.9MB each) takes barely a millisecond. The non-expert parts of the model (the "routing" logic that decides which experts to call) stay permanently in memory, taking up only 5.5GB.
Performance at a glance
2-bit experts: 5.55 tokens/sec (120GB on disk) — best balance of speed and quality
4-bit experts (warm cache): 4.80 tokens/sec (209GB on disk)
Peak single token: 7.05 tokens/sec
RAM used: 6–9GB total, leaving 39GB free for other work
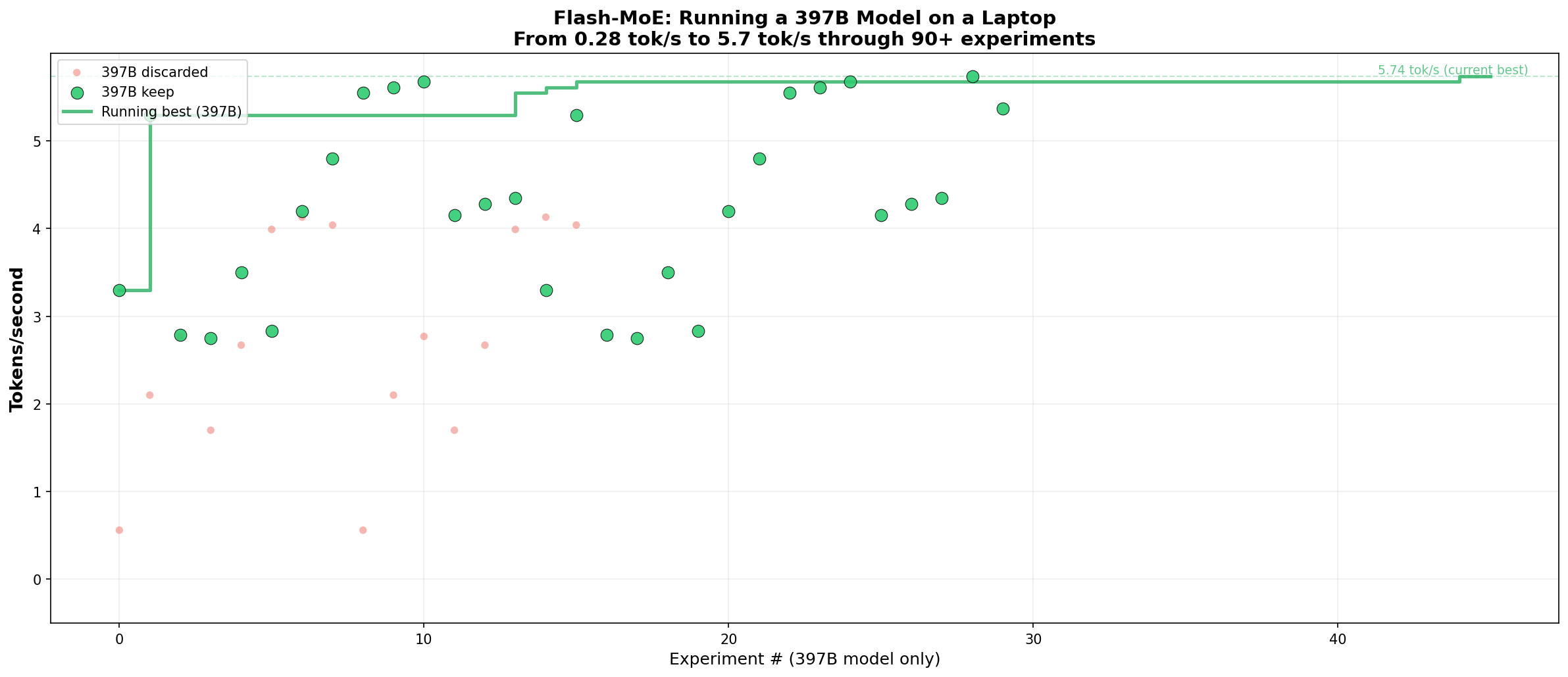
90 experiments in 24 hours — built with Claude
Developer Dan Woods used Claude Code with what he calls an "autoresearch pattern" — letting Claude run 90 optimization experiments automatically, generating highly optimized MLX Objective-C and Metal code at each step. The entire engine — roughly 5,000 lines of C/Objective-C and 1,100 lines of Metal GPU shaders — was built in 24 hours.
Key innovations include 2-bit quantization (compressing expert weights to half the size of standard 4-bit, with virtually no quality loss), deferred GPU computing that processes experts asynchronously, and direct I/O that bypasses the operating system's file cache to avoid memory thrashing.
Try it yourself (if you have a MacBook with 48GB+)
# Clone and build
git clone https://github.com/danveloper/flash-moe
cd flash-moe/metal_infer
make
# Run in 2-bit mode (fastest, 120GB disk)
./infer --prompt "Explain quantum computing" --tokens 100 --2bit
# Interactive chat
./chat --2bitRequirements: MacBook Pro with Apple M3 Max (or similar), 48GB unified memory, 1TB SSD, and macOS 26.2+. You'll also need the model weights — the repo includes extraction scripts.
Why this matters beyond benchmarks
Running a 397B model locally means zero API costs, full privacy, and no internet needed. Until now, models this large required cloud GPU clusters costing hundreds per hour. Flash-MoE proves that Apple Silicon's fast SSD + unified memory architecture can substitute for expensive GPU VRAM — at least for MoE models.
The technique builds on Apple's 2023 research paper "LLM in a Flash," but this is the first open-source implementation that actually delivers usable speeds on consumer hardware. A full technical paper with all 90+ experiments is included in the repository.
For anyone frustrated by cloud AI rate limits and costs, this is a glimpse of a future where the biggest models run on the machine in front of you.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments