AI scores 90% on Python — and 3.8% on unknown languages
EsoLang-Bench tested GPT-5, Claude, and Gemini on five obscure programming languages. The results reveal AI coding is 96% pattern-matching, not reasoning.
A new benchmark called EsoLang-Bench just exposed a massive blind spot in AI coding assistants. Frontier models like GPT-5.2 score around 90% on Python programming tasks — but when tested on five obscure programming languages they've never seen before, that score collapses to just 3.8%.
That's an 85-percentage-point gap. And it suggests the AI writing your code might not truly understand programming — it's just very good at recognizing patterns from its training data.
The experiment that broke every AI model
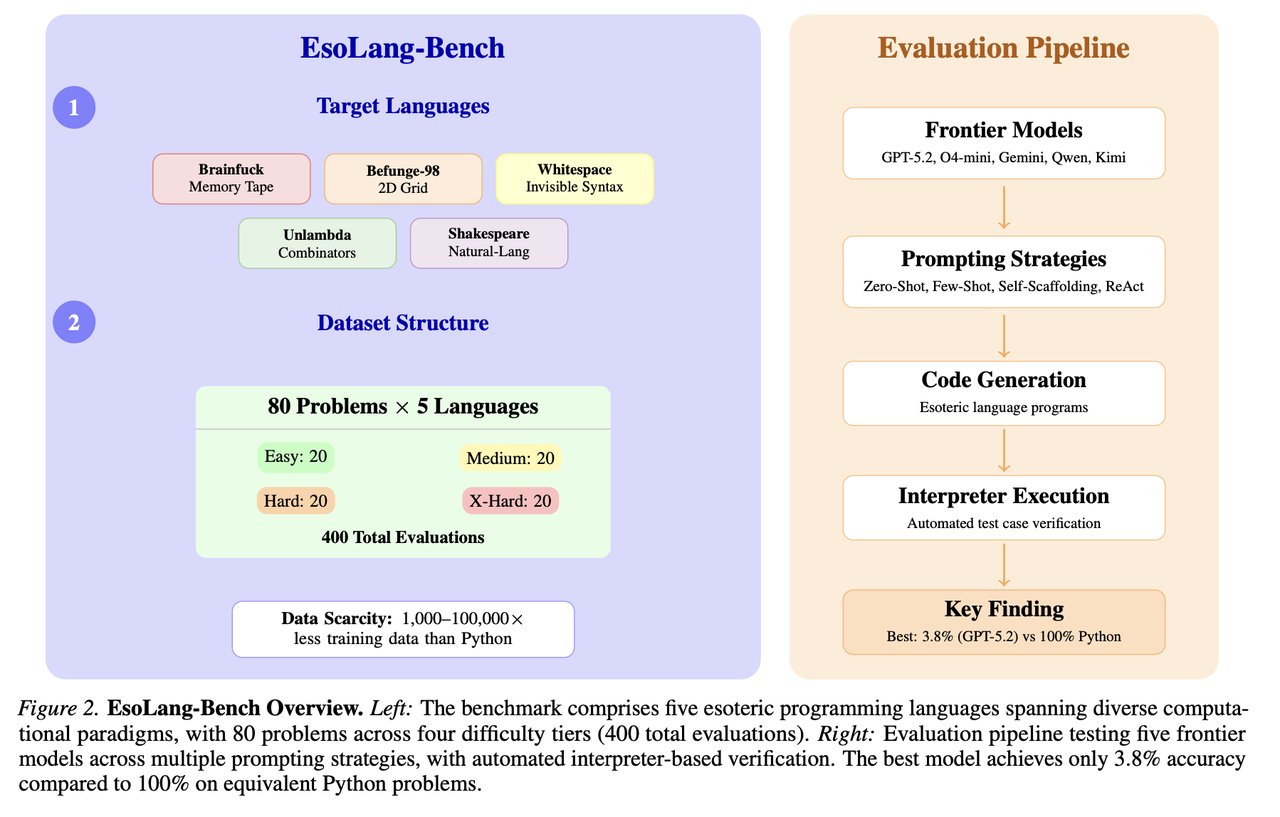
Researchers Aman Sharma and Paras Chopra from Lossfunk Research designed a clever test. They picked five "esoteric" programming languages — weird, intentionally difficult languages that almost nobody uses — and asked the same AI models that ace standard coding benchmarks to solve equivalent problems in these languages.
The languages they chose:
Brainfuck — uses only 8 characters (like +, -, <, >) to write programs. Best AI score: 13.8%
Befunge-98 — code runs on a 2D grid, moving up, down, left, and right. Best AI score: 11.2%
Shakespeare — programs look like Shakespeare plays, with variables named after characters. Best AI score: 2.5%
Unlambda — based on pure mathematical logic with no variables. Best AI score: 1.2%
Whitespace — uses only spaces, tabs, and newlines (invisible characters). Best AI score: 0.0%
Not a single AI model could produce a working Whitespace program. And beyond the easiest problems, every model scored 0% across all five languages.
Why these languages matter
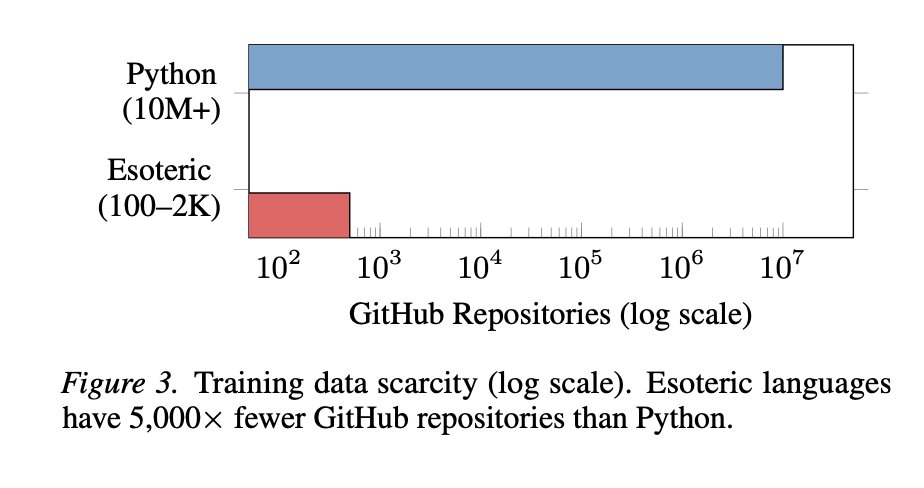
The key insight is that these esoteric languages require the exact same logic as Python — loops, conditionals, arithmetic, input/output. The difference? They have between 1,000 and 100,000 times fewer examples on the internet than Python.
If an AI truly "understood" programming concepts, it should be able to apply them in any language after reading the documentation — just like a human programmer can. The fact that it can't strongly suggests current AI models are matching patterns from training data, not reasoning about code.
Five frontier models, same failure
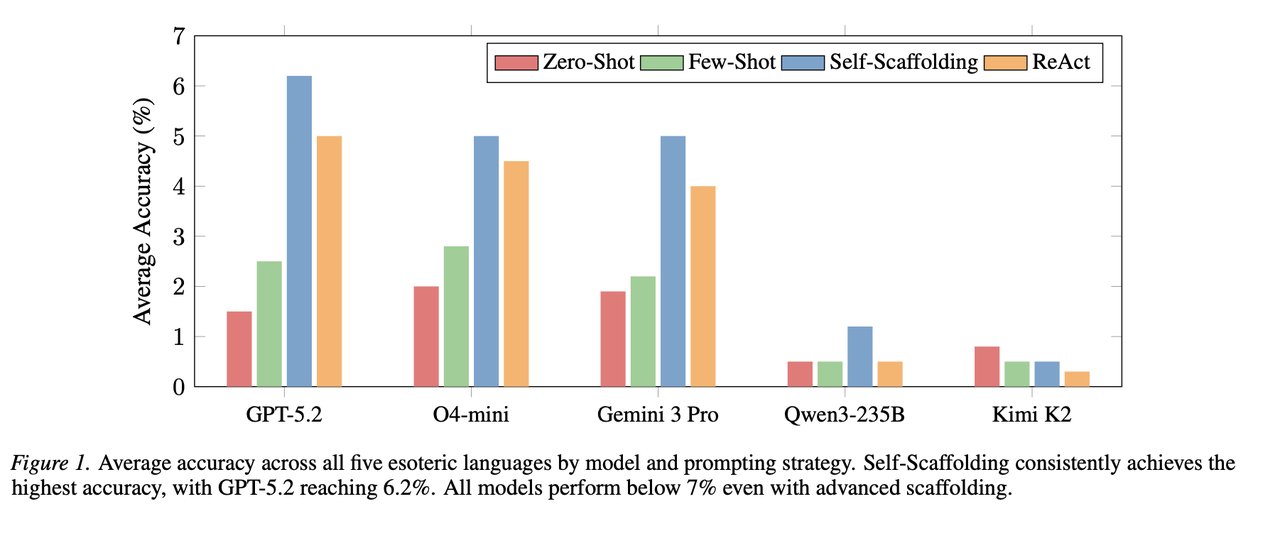
The researchers tested five of the most advanced AI models available: GPT-5.2, O4-mini-high (OpenAI's specialized reasoning model), Gemini 3 Pro, Qwen3-235B, and Kimi K2 Thinking. They tried everything — giving the AI examples, letting it run and debug its own code, even pairing models together as "coder" and "critic."
Nothing worked beyond trivial problems. Giving AI models access to run their code and see errors doubled their scores — but doubling near-zero still leaves you near zero.
What this means if you use AI to write code
This doesn't mean you should stop using Cursor, Claude Code, or GitHub Copilot. These tools are genuinely useful for Python, JavaScript, and other popular languages — precisely because there's so much training data available.
But it's a critical reminder: AI coding assistants are at their best when you understand the code they generate. If you're blindly accepting AI-written code without reviewing it, you're trusting a pattern-matcher, not a programmer.
For developers: Use AI coding tools for boilerplate and repetitive tasks, but double-check any complex logic. The model might produce something that looks right because it resembles patterns from its training, not because it reasoned through the problem.
For non-coders using vibe coding: This is why testing matters. When AI generates an app for you, click every button, test every edge case. The AI doesn't truly understand what it built.
For hiring managers: AI coding benchmarks like HumanEval and SWE-bench may overstate real capability. A 90% benchmark score doesn't mean 90% understanding.
The benchmark anyone can try
EsoLang-Bench is completely open source on GitHub, with the dataset available on their interactive website and HuggingFace. The full research paper is published on arXiv.
pip install -e ".[benchmark,dev]"
from esolang_bench import get_interpreter
interp = get_interpreter("brainfuck")
result = interp.run("++++++[>++++++<-]>.", stdin="")The research is already gaining traction on Hacker News. As one commenter put it: "This is the most honest coding benchmark I've seen in years."
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments