This AI PDF parser just hit #1 on GitHub — 5K stars
OpenDataLoader PDF extracts tables, formulas, and text from any PDF at 90% accuracy — beating every competitor. Free, no GPU, 2 lines of code.
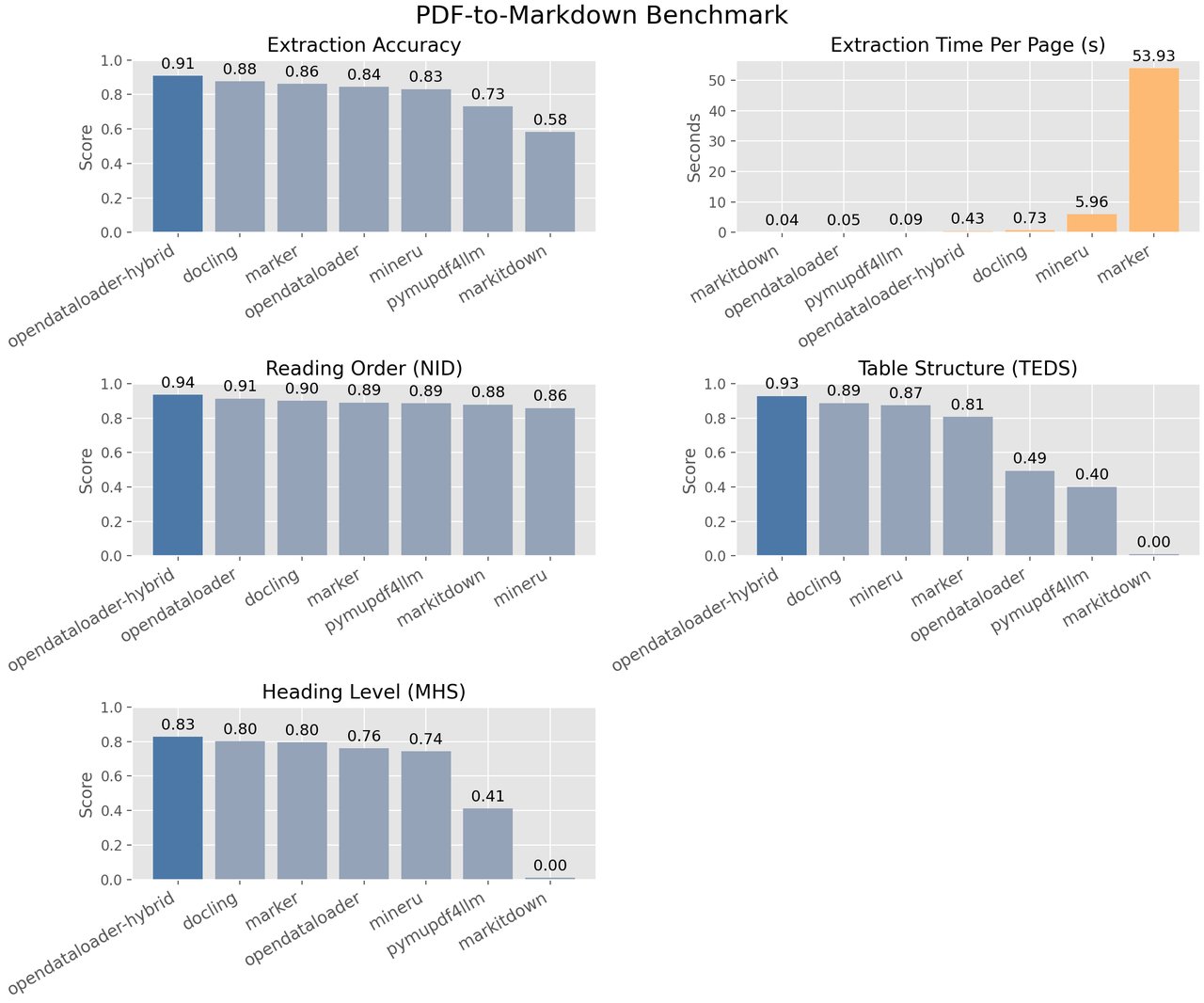
A new open-source PDF parser called OpenDataLoader PDF just exploded on GitHub — gaining 1,394 stars in a single day and reaching 5,000+ total stars. It converts messy PDFs into clean, structured data that AI tools can actually understand, and it ranked #1 across all benchmarks against every major open-source competitor.
Why PDFs Have Been AI's Blind Spot
Anyone who's tried to get AI to read a PDF knows the frustration. Tables come out scrambled. Multi-column layouts get merged into nonsense. Scanned documents are completely ignored. Until now, extracting useful data from PDFs required expensive commercial tools or painful manual cleanup.
OpenDataLoader PDF solves this with a hybrid approach: it uses fast rule-based processing for simple pages (~0.05 seconds per page) and routes complex pages — like nested tables, math formulas, and charts — to an AI backend for deeper analysis.

Benchmark Champion: 90% Overall Accuracy
Tested against 200 real-world PDFs including scientific papers, financial reports, and multi-column documents, OpenDataLoader beat every open-source alternative:
OpenDataLoader (hybrid): 90% overall — 94% reading order, 93% tables, 83% headings
Docling: 86% overall
Marker: 83% overall
MinerU: 82% overall
The full benchmark dataset and code are published on GitHub so anyone can verify the results independently.
Built for AI Pipelines — Not Just Humans
What makes this tool especially powerful is that every extracted element includes bounding box coordinates (precise X/Y positions on the page). This means when an AI chatbot gives you an answer based on a PDF, it can point you to the exact location on the exact page where it found that information — no more blind trust.
It also includes built-in prompt injection detection (catching hidden malicious instructions that someone might embed in a PDF to trick AI tools) and supports 80+ languages for scanned document recognition.
Who Should Care
If you work with documents daily — contracts, invoices, research papers, government forms — this tool can extract structured data in seconds instead of hours of manual copy-pasting.
If you're building AI tools — the LangChain integration means you can plug it directly into your AI chatbot or search system with minimal code.
If you care about accessibility — OpenDataLoader is building a free auto-tagging feature (coming Q2 2026) that converts untagged PDFs into accessible formats, addressing regulatory requirements across the EU, US, and globally.
Try It in 2 Lines
pip install -U opendataloader-pdf
opendataloader-pdf your-document.pdfOr in Python:
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=["file.pdf"],
output_dir="output/",
format="markdown"
)No GPU required. No API keys. No cloud dependency. It runs entirely on your machine under the Apache 2.0 license (free for any use, including commercial). Built by Hancom, the South Korean software company behind the Hangul word processor.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments