Kimi just found a trick that cuts AI training costs 25%
Moonshot AI's Attention Residuals technique lets AI models reach the same performance with 25% less computing power. The code is free and open source on GitHub.
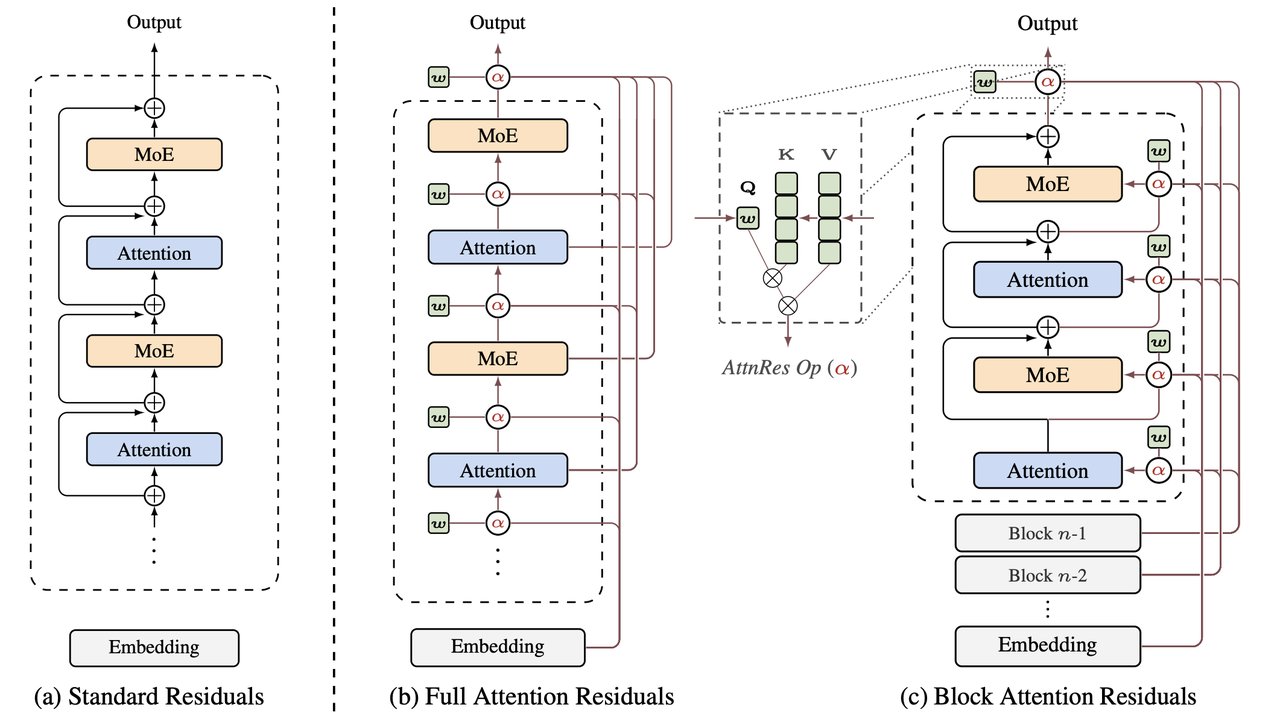
The team behind Kimi — one of China's most popular AI chatbots — just published a technique that could save AI companies millions of dollars. It's called Attention Residuals, and the core idea is surprisingly simple: let each layer of an AI model choose which earlier layers to listen to, instead of forcing them all to blend together equally.
The result? AI models that reach the same quality with 25% less computing power. That's not a minor tweak — in an industry spending billions on GPU clusters, a 25% efficiency gain translates to enormous real-world savings. The paper is trending on Hacker News with 151 points, and the code has hit 2,300 GitHub stars.
Why every AI model wastes computing power right now
To understand why this matters, imagine a factory assembly line. In today's AI models (called Transformers — the architecture behind ChatGPT, Claude, and Gemini), information passes through dozens of processing stages called "layers." Each layer is supposed to refine the output.
The problem: every layer receives a blended mix of everything that came before, with equal weight. It's like forcing a chef to taste every ingredient at once instead of selectively picking what they need. As models get deeper (more layers), this blended signal becomes noisier and harder to work with.
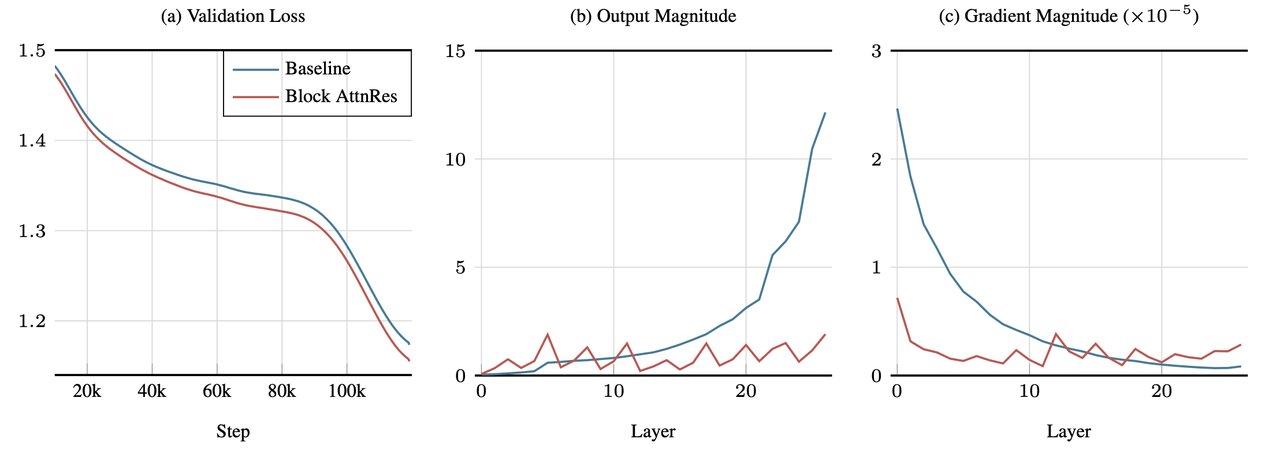
Moonshot AI calls this "hidden-state magnitudes growing unboundedly" — in plain English, the signal gets louder and messier with each layer, drowning out useful information.
The fix: let layers be selective
Attention Residuals replaces the "blend everything equally" approach with a smarter one. Each layer gets a learned ability to pay attention to specific earlier layers and ignore others. The technical term is "softmax attention over depth" — but the intuition is simple:
Before: Every layer gets the same blended soup of all previous outputs.
After: Each layer picks and chooses which earlier outputs are most useful for its specific task.
The practical variant — called Block Attention Residuals — groups layers into blocks of about 8, keeping the memory overhead minimal. Moonshot AI says it works as a "drop-in replacement" that requires minimal code changes.
Real numbers: what improved
Moonshot tested this on their Kimi Linear model (48 billion total parameters, 3 billion active at once), trained on 1.4 trillion words of text. The improvements across standard AI benchmarks:
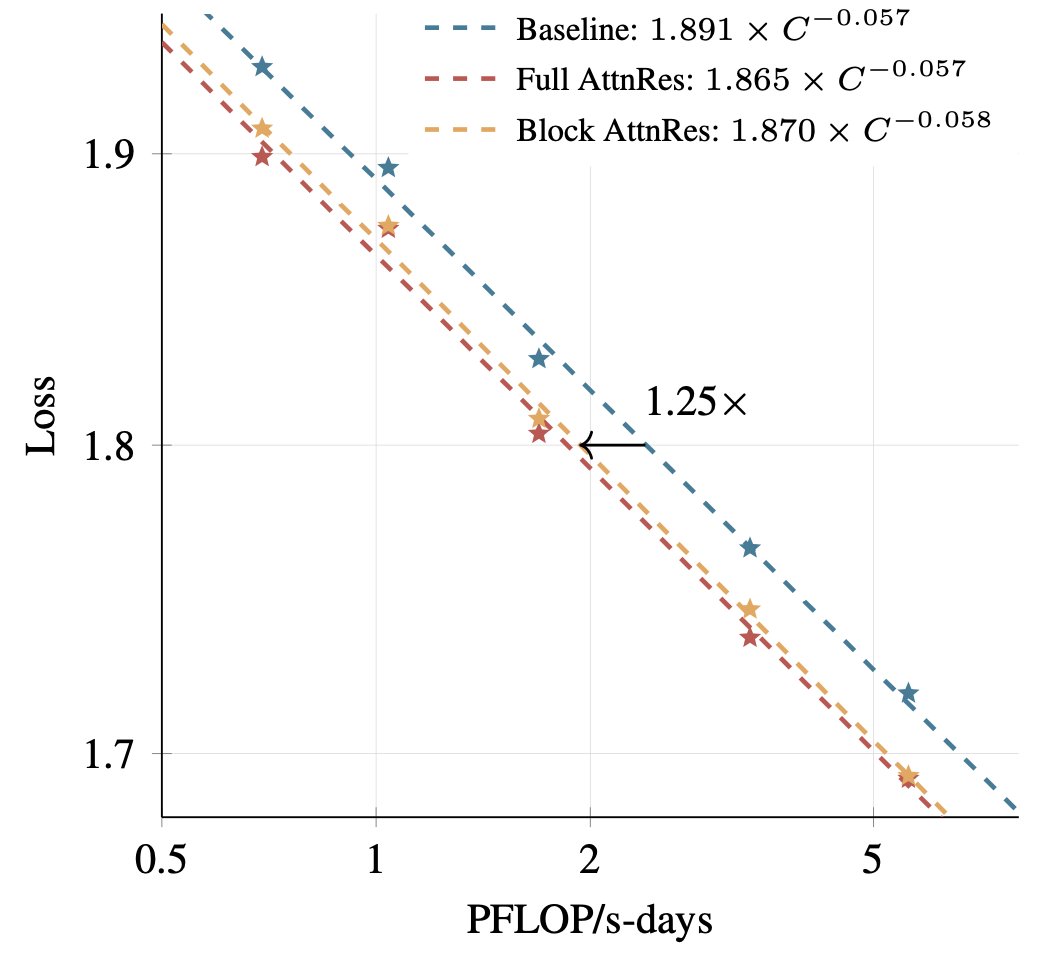
The scaling chart above tells the real story: a model with Attention Residuals trained on X compute matches a standard model trained on 1.25X compute. That's the 25% savings.
Who benefits from this?
AI companies and cloud providers stand to save the most. When training a frontier model costs $100 million or more, a 25% cut means $25 million saved per run. Those savings can go toward training better models — or lowering prices for everyone.
Researchers and smaller teams benefit too. If your GPU budget is tight, this technique lets you reach performance levels that were previously out of reach. The code is open source under Apache 2.0, so anyone can use it.
End users may feel the impact indirectly: cheaper training means faster iteration, which means better AI tools reaching the market sooner. The technique also reduces the environmental footprint of AI training — fewer GPUs burning power for the same result.
The bigger context
This paper is part of a growing trend: making AI more efficient instead of just bigger. While some labs chase trillion-parameter models, Moonshot AI is showing that architectural cleverness can deliver similar gains at a fraction of the cost. The technique applies beyond just Kimi — any company building Transformer-based models (which is essentially everyone) can adopt it.
The full research paper and code are freely available. Whether you're building AI models or just watching the industry evolve, this is the kind of foundational work that quietly reshapes what's possible.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments