Meta just built AI that translates 1,600 languages
Meta's Omnilingual MT is the first AI translation system covering 1,600 languages — and its smallest models outperform ones 70x their size.
Most AI translation tools — including Google Translate — cover around 130 to 200 languages. That leaves billions of people who speak minority or endangered languages without usable translation. Meta just changed that.
On March 17, Meta's research team published Omnilingual MT (OMT), the first machine translation system ever benchmarked on more than 1,600 languages. It's not just broader — it's also shockingly efficient: models as small as 1 billion parameters match or beat a 70-billion-parameter AI at translation quality.

From 200 languages to 1,600 — here's how
Meta's previous translation project, NLLB (No Language Left Behind), reached about 200 languages. Omnilingual MT covers 8x more — including hundreds of languages that have never had AI translation support.
The team built two model types to make this work:
OMT-LLaMA — A decoder-only model (the same architecture behind ChatGPT) built on LLaMA 3, available in 1B, 3B, and 8B sizes. It uses a technique called retrieval-augmented translation: when translating an obscure language, it pulls in relevant example translations at inference time to improve accuracy.
OMT-NLLB — An encoder-decoder model (a two-part system where one part reads the input and another generates the output) that can exploit non-parallel data — meaning it can learn from texts that aren't direct translations of each other.
The team also expanded the vocabulary from 128,000 to 256,000 tokens, which dramatically improves how well the system handles non-Latin scripts like Devanagari, Arabic, Ge'ez, and hundreds of others. In practice, this means fewer garbled characters and more accurate translations for languages that use complex writing systems.
Tiny models, massive results
Here's the number that matters most: even the 1-billion-parameter model matches or exceeds a 70-billion-parameter general-purpose AI at translation tasks. That's a 70x size reduction with equal or better performance.
Why does this matter? Smaller models are dramatically cheaper to run. A 70B model needs expensive GPU clusters. A 1B model can run on a single consumer-grade GPU — or even a phone. This makes it economically viable to deploy translation for languages that no company would spend millions to support with a massive model.
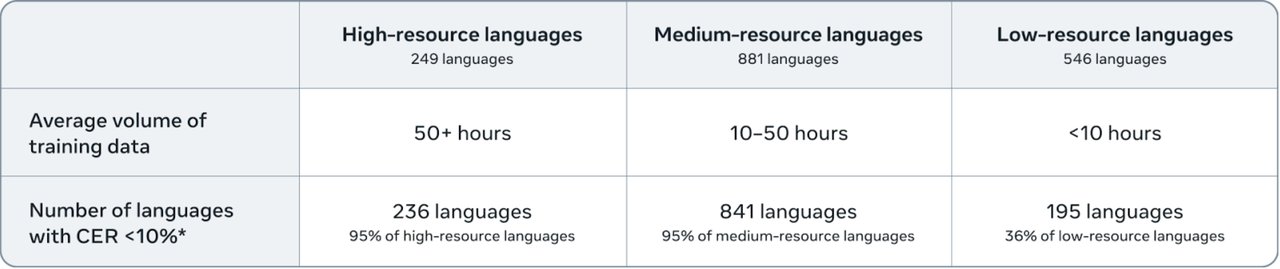
What it actually covers
The system's coverage works in tiers:
~400 languages — "sufficiently well understood" (conveying core meaning reliably). This alone doubles what any previous system achieved.
~1,600 source languages — the system can translate from these languages with "non-trivial" quality.
~1,200 target languages — the system can translate into these languages.
The researchers identified a critical "generation bottleneck" — while large AI models can understand many obscure languages, they often fail to generate coherent text in them. OMT's specialized training specifically addresses this gap.
New evaluation tools for languages nobody tracked before
One of the team's biggest contributions isn't the model itself — it's the tools to measure quality. They created:
- BOUQuET — the largest multilingual evaluation dataset ever assembled, manually extended across linguistic families
- BLASER 3 — a quality estimation tool that works without reference translations (critical for languages where professional translators don't exist)
- OmniTOX — a toxicity classifier that catches harmful content across languages
The evaluation datasets and a public leaderboard are freely available on HuggingFace under a CC-BY-SA 4.0 license.
Who this matters for
If you work with multilingual communities — humanitarian organizations, international NGOs, language preservation projects — this is the first time AI translation has been practical for hundreds of languages that Google Translate simply doesn't support.
If you're building apps for global audiences — the small model sizes mean you could add translation for rare languages without massive infrastructure costs.
If you speak a minority language — this research is a step toward AI tools that don't ignore you. While Meta hasn't released the models publicly yet (only the evaluation tools), the paper and architecture are open, and Meta has historically open-sourced its translation models.
The research was led by Marta R. Costa-Jussà and a team of 29 researchers at FAIR (Meta's AI research lab). The full paper is available on arXiv.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments