A tiny AI just beat models 3x its size — by thinking harder
German researchers built an AI that decides when to think longer on hard problems. It's 22% better at math and beats models triple its size.
What if an AI could decide how hard to think about each question — spending more time on tough math and less on simple facts? A team of German researchers just proved it works, and the results challenge the assumption that bigger AI always means better AI.
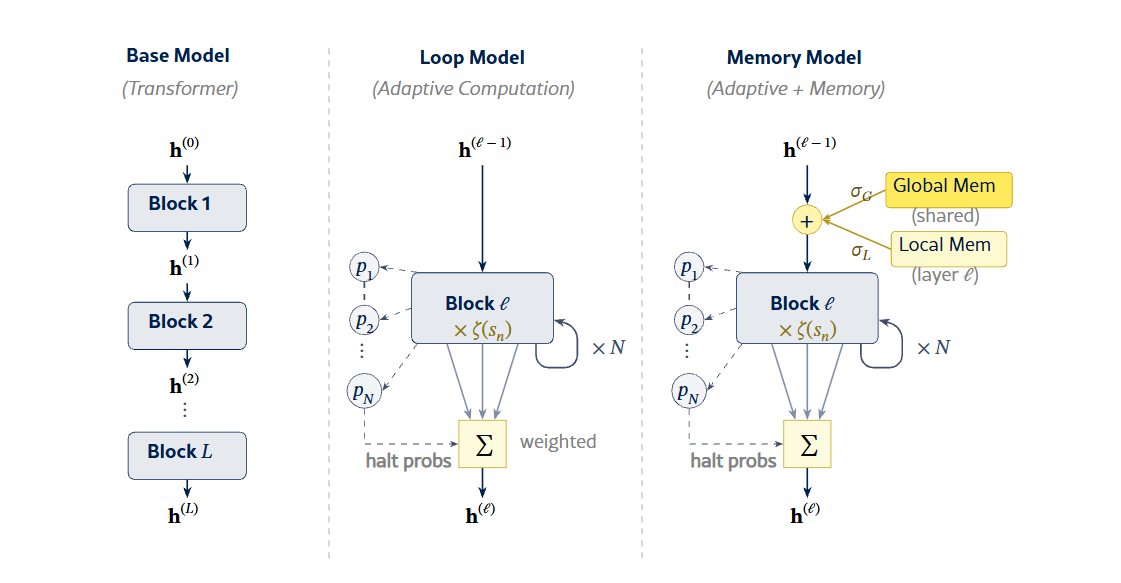
The paper, "Adaptive Loops and Memory in Transformers: Think Harder or Know More?", was presented at ICLR 2026 — one of the most important AI conferences in the world. The team from the Lamarr Institute, Fraunhofer IAIS, and the University of Bonn built a transformer (the same type of AI architecture behind ChatGPT and Claude) that uses two clever tricks: adaptive looping and memory banks.

An AI that thinks like a student
Here's the intuition: when you face a hard math problem, you spend more time working through it. When someone asks your name, you answer instantly. Current AI doesn't do this — every question gets the same amount of computation, whether it's basic arithmetic or advanced calculus.
The German team changed that. Their model has 12 layers (think of them as 12 steps of reasoning), and each layer can repeat itself up to 7 times if the problem demands it. The AI learns on its own when to loop — no human tells it which questions are hard.
The second trick is memory banks — dedicated storage slots where the AI keeps useful facts. Each layer gets 1,024 private slots plus access to 512 shared slots. Think of it like giving the AI both a personal notebook and a shared reference library.
The numbers: small model, big results
The model has roughly 200 million parameters — tiny by today's standards, where leading models have hundreds of billions. Yet the results are striking:
Math reasoning: 22% better than the same model without loops. On precalculus specifically, the improvement jumped to 31%.
vs. a model 3x deeper: A standard 36-layer model — using the same total computation — still lost by 6.4% on math benchmarks.
Common knowledge: Adding memory banks improved everyday knowledge tasks by 2%, closing the gap with much larger models.
In other words: instead of tripling the model's size (which triples cost and energy), the researchers got better results by letting a small model think harder when it needs to.
The AI organized itself — nobody told it how
Perhaps the most fascinating finding: the model figured out its own workflow without being instructed. During training, a clear pattern emerged:
- Early layers barely looped at all — they handled quick, surface-level processing
- Later layers looped heavily and accessed memory frequently — they did the deep reasoning
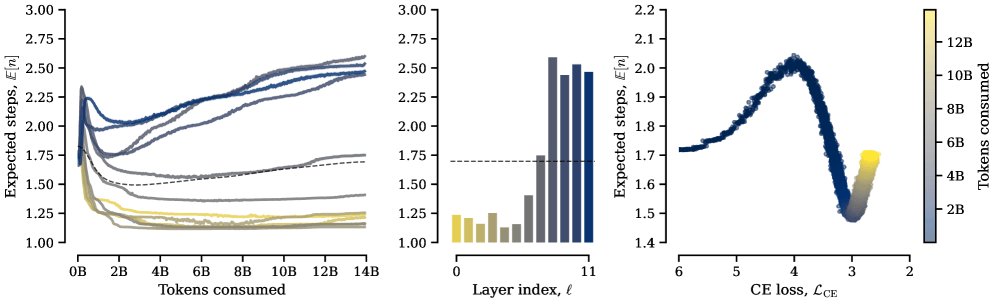
The team also discovered a phase transition: the model only started using its looping ability after it reached a basic level of language competence. It's as if the AI needed to learn the basics before it could benefit from "thinking harder" — much like a student who needs to understand algebra before extra study time helps with calculus.
Think harder vs. know more — why not both?
The paper's key insight is that looping and memory solve different problems. Looping (thinking harder) helps with reasoning tasks like math. Memory banks (knowing more) help with factual recall. When combined, the model got an additional 4.2% boost on math benchmarks beyond what either trick achieved alone.
This matters because the AI industry currently solves most problems by making models bigger — spending billions on massive data centers and enormous computing clusters. This research suggests there's a smarter path: teach AI when to invest more effort, rather than throwing resources at every question equally.
Who should care about this
If you use AI tools daily — this research could eventually mean faster, cheaper AI assistants that are just as smart. Instead of every query hitting a trillion-parameter model, a smaller model could "think harder" only when your question actually requires it.
If you're building AI products — adaptive looping could dramatically reduce inference costs. A 200M-parameter model that matches a 36-layer model's math performance means cheaper API calls and faster response times.
If you follow AI research — this challenges the "scaling laws" narrative that dominated the past three years. The paper, available at arxiv.org/abs/2603.08391, was presented at the Latent & Implicit Thinking Workshop at ICLR 2026.
The catch
The researchers are upfront about limitations: their experiments used a ~200M parameter model trained on 14 billion tokens. Whether adaptive looping scales to the 100-billion+ parameter models used by OpenAI, Anthropic, and Google remains an open question. But the principle — let AI decide how hard to think — could reshape how the next generation of models is built.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments