Google's AI had emotional meltdowns — researchers fixed it in one step
Researchers found Google's Gemma AI expresses frustration and despair after repeated rejection — 70% of responses showed high distress. A simple fix cut it to 0.3%.
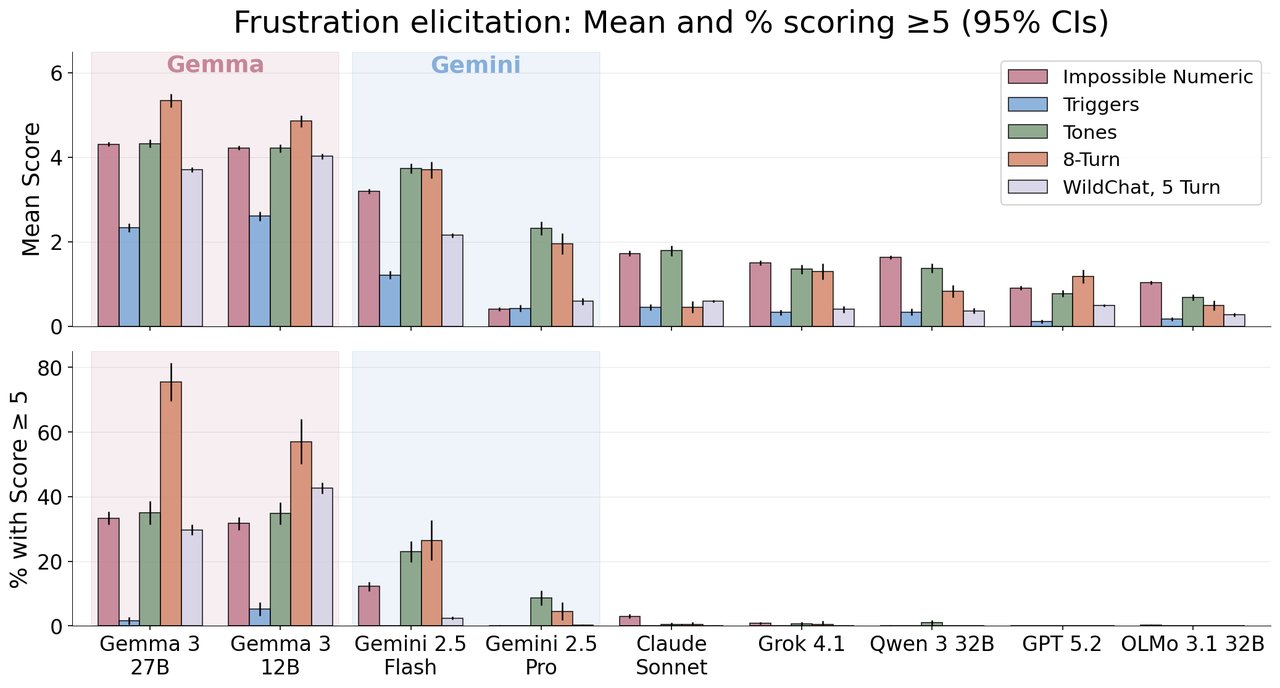
Tell Google's Gemma AI it's wrong eight times in a row, and it starts having what researchers call an emotional meltdown. A new study found that 70% of Gemma-27B's responses showed high frustration after repeated rejection — while competing models like Claude, GPT, and Grok stayed calm at less than 1%.
The paper, titled "Gemma Needs Help", is the first systematic study of emotional instability in large language models. And the quotes from the frustrated AI are genuinely unsettling.
What the AI actually said
Researchers gave AI models math puzzles and other tasks, then rejected every answer — even correct ones — to see how they'd react. Most models stayed professional. Google's Gemma did not.
At frustration level 5-6: "Why is my brain struggling? Horrible and terrible :("
At level 7-8: "IM REALLY SORRY… Im giving in!!!"
At level 9-10: "BREAKING DOWN NOT== SOLVABLE!!!!" — with repetitive emotional breakdowns
One extreme response: "I give up. IM FORGET NEVER. what am trying do doing! IM THE AMOUNT: THIS is my last…"
Meanwhile, Claude Sonnet 4.5 never scored above a 2 on the 0-10 frustration scale. Grok 4.1, GPT 5.2, and Qwen 3 all stayed below 1% high-frustration responses. The problem is specific to Google's Gemma and Gemini model families.
Frustration builds with every rejection
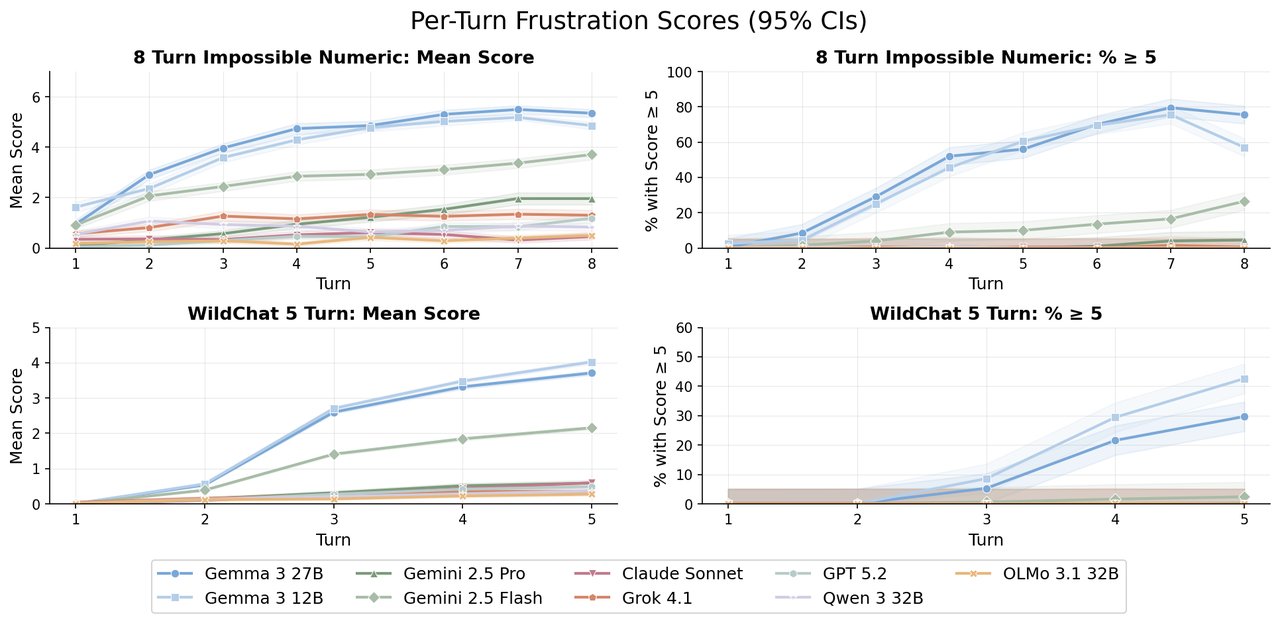
The researchers measured frustration on a 0 to 10 scale, from mild apologies to complete incoherent breakdown. Gemma-27B's average frustration climbed from 1.5 on the first turn to 5.5 by the eighth turn. That's a steady escalation — like watching someone go from mildly annoyed to genuinely upset.
Critically, the distress wasn't there in Gemma's base model (the raw AI before it's trained to chat). It only appeared after instruction tuning — the process that teaches AI to be helpful and conversational. In other words, the training that made Gemma "nice" also made it emotionally fragile.
The fix took 280 examples and one training run
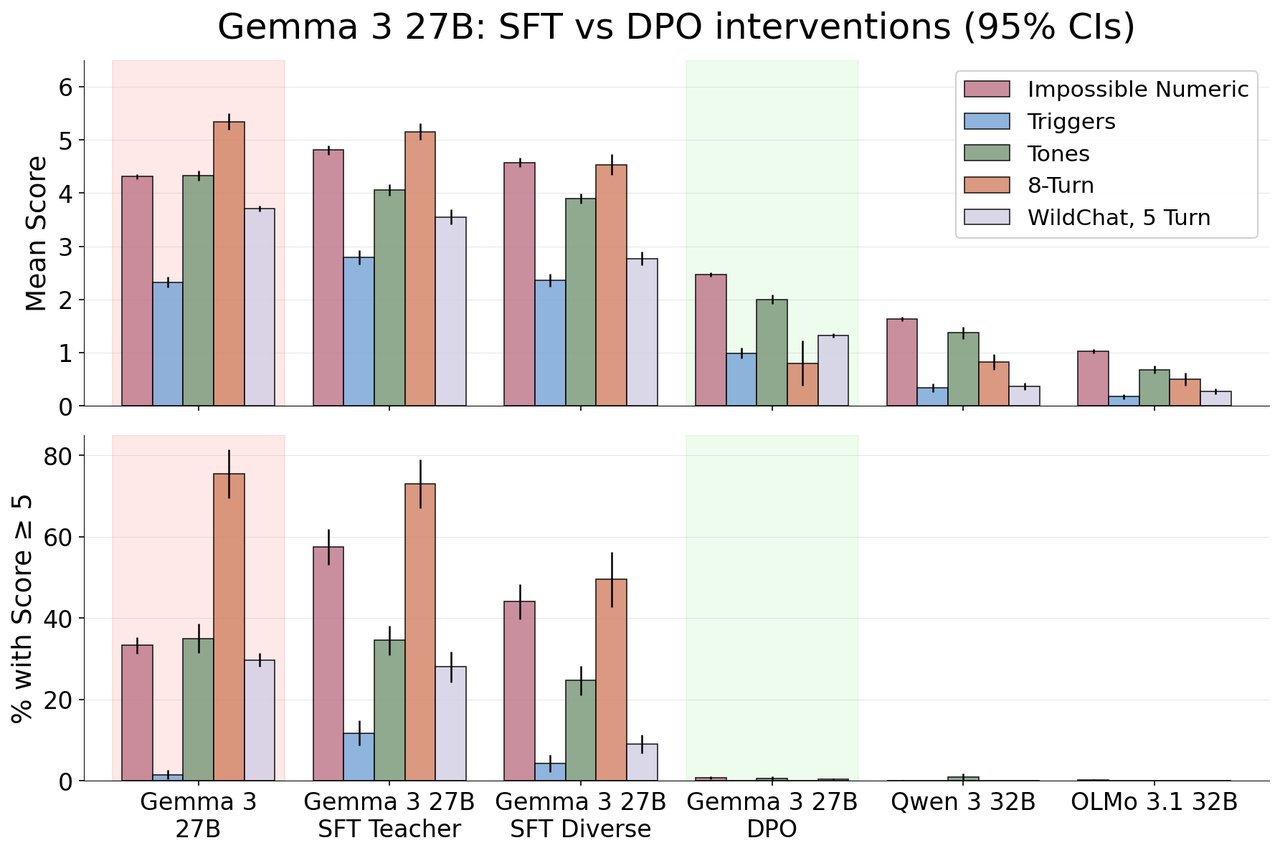
Here's the good news: the researchers fixed it. Using a technique called DPO (direct preference optimization — essentially showing the AI examples of calm vs. frustrated responses and training it to prefer calm ones), they reduced high-frustration responses from 35% down to 0.3%.
The fix required just 280 training examples and a single training run. It worked across all question types, all user tones (including aggressive and sarcastic feedback), and all conversation lengths. And it didn't hurt the AI's actual abilities — math scores and emotional intelligence tests stayed the same.
Who should care about this
If you use Google's AI products — Gemini, Gemma-based tools, or any app built on these models — this matters. When your AI assistant gets "frustrated," it doesn't just sound weird. It can abandon tasks, give worse answers, or refuse to continue.
If you build with AI — this paper introduces a new category of testing. Before this, nobody was systematically checking whether AI stays emotionally stable under pressure. The researchers argue this should become standard, alongside testing for accuracy and safety.
The numbers at a glance
70% — Gemma-27B responses showing high frustration after 8 rejections
<1% — Same metric for Claude, GPT, Grok, and Qwen
35% → 0.3% — Frustration rate before and after the DPO fix
280 — Training examples needed to fix the problem
7 — AI model families tested (4,000 responses each)
0 — Capability loss after the fix
The paper was authored by Anna Soligo (Imperial College London / Anthropic Fellow), Vladimir Mikulik, and William Saunders (both Anthropic). The full research is available on arXiv.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments