NVIDIA's free AI just won gold at 3 international olympiads
Nemotron-Cascade 2 won gold medals at the Math and Programming Olympiads using 20x fewer resources than the only other AI to do it. It's free and open source.
NVIDIA just released Nemotron-Cascade 2, an AI that won gold medals at three of the hardest academic competitions in the world — the International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals. The catch? It uses 20 times fewer resources than the only other AI that achieved the same feat.
Why this matters: intelligence per watt
Until now, only one open AI system had earned gold medals at all three competitions: DeepSeek's V3.2-Speciale, a massive system with 671 billion total parameters and 37 billion active. That kind of power requires expensive server hardware most people and companies can't afford.
Nemotron-Cascade 2 achieves the same results with just 30 billion total parameters and only 3 billion active at any time. Think of it like a team of specialists — instead of keeping every expert in the room simultaneously, it calls in only the ones it needs for each task. NVIDIA calls this "remarkably high intelligence density."
Gold medal scorecard
IMO 2025 (Math Olympiad): 35 points — gold medal level
IOI 2025 (Programming Olympiad): 439.3 points — gold medal
ICPC World Finals 2025: solved 10 out of 12 problems
AIME 2025 (math qualifying exam): 92.4% accuracy (98.6% with tool use)
What it can actually do
Beyond competition math, Nemotron-Cascade 2 is designed as a practical AI for real work. It runs in two modes:
Thinking mode — the AI shows its step-by-step reasoning before giving a final answer. Useful when you need to verify how it reached a conclusion.
Instruct mode — the AI gives direct answers without showing its work. Faster for straightforward questions and everyday tasks.
It also supports tool use — meaning it can write and run Python code to solve problems, verify calculations, and interact with external systems. On the LiveCodeBench coding benchmark, it scored 87.2% (88.4% with tools).
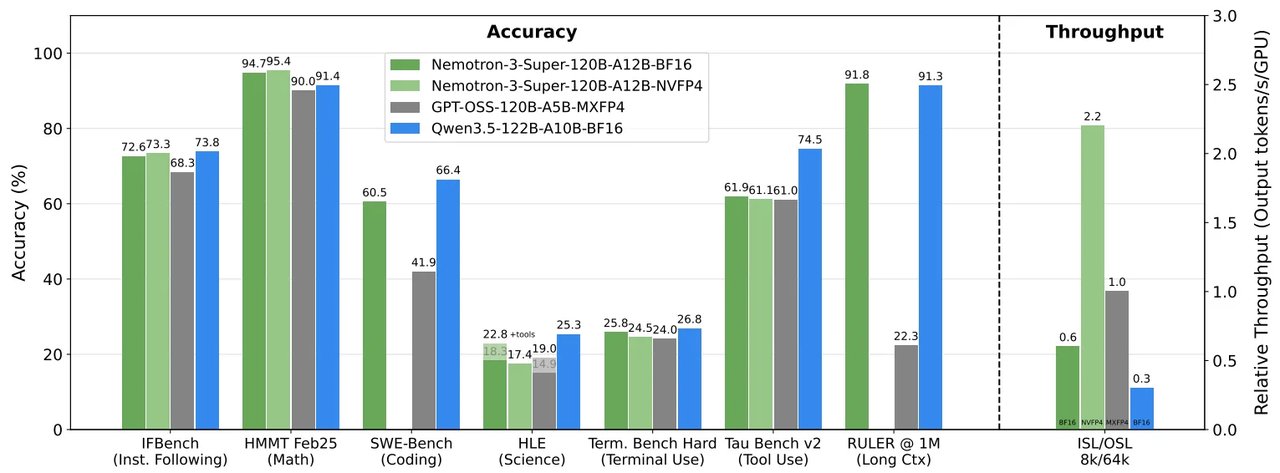
Who should pay attention
If you're a developer or researcher: This is a free, open-weight model you can download and run today. It competes with models that cost significantly more to operate. The 3B active parameter design means you need far less GPU memory than typical 30B+ models.
If you're a business: Running AI in-house (rather than paying per API call) becomes more viable when a model this capable fits on more affordable hardware. NVIDIA released the model under its Open Model License with full checkpoints and training data.
If you're watching the AI race: This signals that raw model size is becoming less important. The gap between the biggest models and efficient ones is shrinking fast. A year ago, winning math olympiads required trillion-parameter systems. Now a 30B model does it.
Try it yourself
The model is available on Hugging Face with full documentation. Here's a quick Python setup:
pip install transformers
from transformers import AutoTokenizer
model_name = 'nvidia/Nemotron-Cascade-2-30B-A3B'
tokenizer = AutoTokenizer.from_pretrained(model_name)
messages = [
{"role": "user", "content": "Solve: find all primes p where p^2 + 2 is also prime"}
]
# Enable thinking mode to see reasoning
prompt = tokenizer.apply_chat_template(
messages, tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)The model supports quantized versions (4-bit, 8-bit) on Hugging Face for running on consumer GPUs, and community members have already created GGUF (a format for running AI locally) and MLX (optimized for Apple Silicon) versions.
The bigger picture: efficient AI is winning
This release continues a clear trend: the smartest AI no longer needs to be the biggest. Mistral's Small 4 proved a compact model could match larger competitors. Flash-MoE showed a 397B model could run on a MacBook. Now NVIDIA proves a 3B-active-parameter system can earn gold medals at international competitions.
The research paper details the training technique — called "Cascade RL with multi-domain on-policy distillation" — which essentially trains the model using the best available teacher for each specific skill domain, preventing it from getting worse at one thing while getting better at another.
With 3,300+ downloads in its first few days and 195 likes on Hugging Face, the developer community is already building on it.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments