A $1,400 AI device just got exposed — using its own ads
A researcher reverse-engineered TiinyAI's $1,400 Pocket Lab from marketing photos alone — and found a $400 GPU outperforms it 10x.
A hardware analyst just tore apart TiinyAI's $1,400 "Pocket Lab" — a portable AI device that raised $1.7 million on Kickstarter from 1,266 backers — without ever touching the device. Using nothing but the company's own marketing photos, renders, spec sheets, and public records, they exposed a product that appears to dramatically overstate what it can actually do.
The findings are striking: a $400 graphics card outperforms it by 5–10x. And the "120 billion parameter model" the company advertises? Only 5.1 billion parameters are actually working at any given moment.

What the marketing says vs. what the hardware does
TiinyAI markets the Pocket Lab as a device that "runs 120B parameter models at 20 tokens per second" — implying you're getting a powerful AI brain in a portable box. For $1,399, that sounds like a steal.
But the researcher identified a critical detail the marketing buries: the "120B model" uses something called Mixture of Experts (MoE) — a design where only a small fraction of the model's brain is active at any time. In this case, only 5.1 billion parameters fire per response, not 120 billion. That's like advertising a 200-room hotel when only 8 rooms are ever open.
- Short conversations (256 tokens): 16.85 tokens/sec — decent
- Medium conversations (8K tokens): 12 tokens/sec — slowing down
- Long documents (32K tokens): 6 tokens/sec — noticeably sluggish
- Full context (64K tokens): 4.47 tokens/sec — and a 28-minute wait before the first word appears
For comparison, an NVIDIA RTX 4060 Ti (a $400 consumer graphics card) handles similar workloads at 70–90 tokens per second.
The hidden bottleneck inside the box
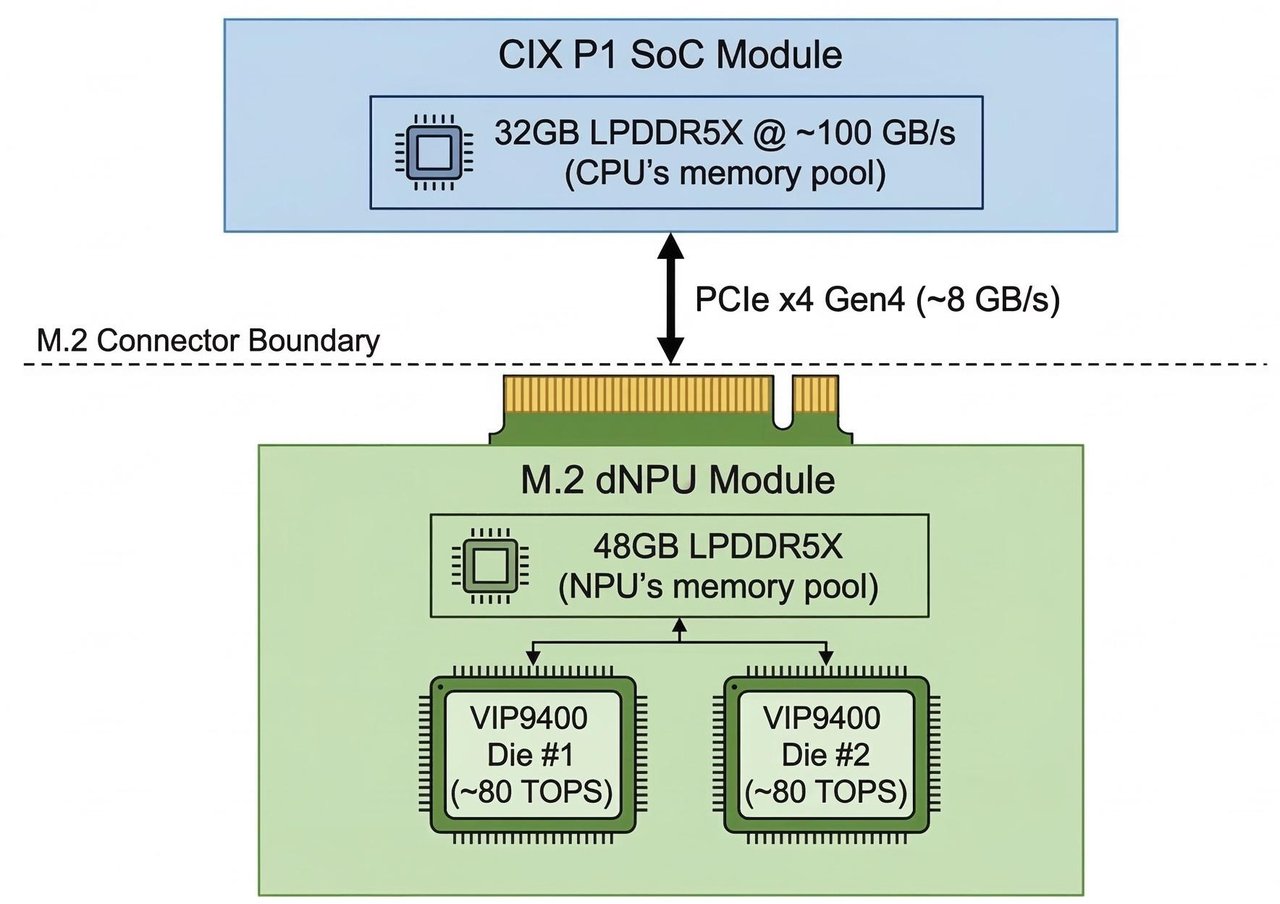
By analyzing X-ray-style renders from TiinyAI's own promotional materials, the researcher identified the device's core problem: it has two separate memory pools that can't talk to each other fast enough.

The device splits its 80GB of memory into a 32GB pool on one chip and a 48GB pool on another. Internally, each pool runs fast — about 100 GB/s. But the bridge connecting them? Only 6–8 GB/s. That's like connecting two highways with a single-lane country road.
Any AI model that needs data from both pools — which most serious models do — hits this bottleneck repeatedly, causing the dramatic slowdowns seen in the benchmarks above.
Where did the research actually come from?
The software powering the Pocket Lab — called PowerInfer — was originally published by Shanghai Jiao Tong University's IPADS lab in December 2023. TiinyAI was founded in January 2024, one month later. The company's GitHub page hosts what appears to be a fork (a copy) of the original university research.
This isn't illegal, but it raises questions about how much original engineering TiinyAI actually did — and whether backers understand they're paying $1,400 for a hardware shell around publicly available academic research.
The transparency problem
The researcher also flagged concerns about who's actually behind the company:
- No visible CEO, CTO, or founder on the company website or Kickstarter page
- LinkedIn shows only a hidden VP, a marketing director, a Hong Kong VC analyst, and an intern
- Incorporated in Delaware but appears to operate from China/Hong Kong
- $1.7 million in backer funds with no clear public accountability structure
The Kickstarter campaign set an artificially low $10,000 goal and blew past it at 17,377% funded — a common tactic that makes campaigns look more successful than their actual targets.
What to check before buying any AI hardware
This investigation highlights a growing problem in AI consumer hardware: marketing that uses technically true but deeply misleading claims. If you're considering any AI device, here's what this case teaches:
Ask these questions before spending:
- "120B parameters" — but how many are active per response?
- "20 tokens/sec" — at what context length? Short test prompts or real conversations?
- Who are the founders? Can you find them on LinkedIn?
- Is the underlying technology original, or based on open-source research?
- Could a consumer GPU (like the $400 RTX 4060 Ti) do the same job faster and cheaper?
The full reverse-engineering analysis is available at bay41.com. The device is scheduled to ship in August 2026 — but with these findings now public, backers may want to reconsider.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments