He let AI re-run his old research — 42 experiments, one day, 54% better
A PhD researcher used Karpathy's autoresearch framework with Claude Code to run 42 experiments on an abandoned project in a single day — cutting errors by 54%.
A machine learning researcher just dusted off a research project he'd shelved — and let an AI agent run 42 experiments on it in a single day. The result: a 54% improvement in accuracy, with the AI doing all the coding, testing, and decision-making on its own.
The story, which hit 318 points on Hacker News, shows exactly what "autoresearch" looks like in practice — and where AI still falls short.
What happened
Yogesh Kumar, a PhD graduate from Aalto University, had an old research project called eCLIP — a system that teaches AI to understand images by focusing on specific regions (like how a doctor looks at a specific part of an X-ray). He adapted it to work with a dataset of ~11,000 Japanese woodblock prints.
Instead of manually tweaking the code and re-running experiments himself, he used Andrej Karpathy's autoresearch framework — a system where an AI agent (in this case, Claude Code) follows a tight loop:
- Come up with a hypothesis ("what if I change this setting?")
- Edit the training code
- Run the experiment
- Check the results
- Keep the change if it worked, undo it if it didn't
- Repeat
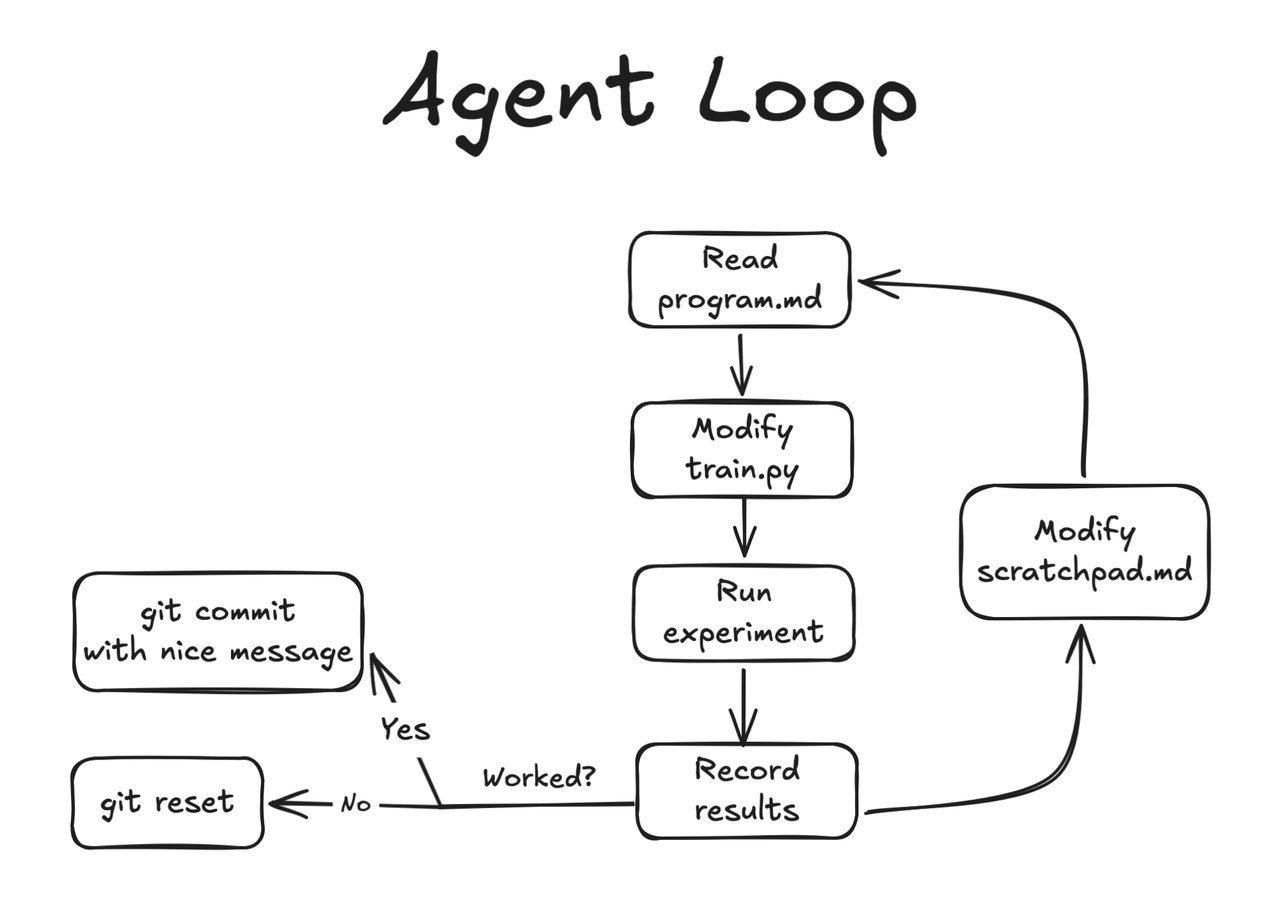
42 experiments, 13 keepers
Over the course of a single day, the AI agent ran 42 experiments. Of those, 13 actually improved the model — the other 29 were automatically reverted. The biggest single win? Fixing a temperature parameter (a setting that controls how "confident" the AI is in its predictions), which alone cut errors by 113 points on the mean rank metric.
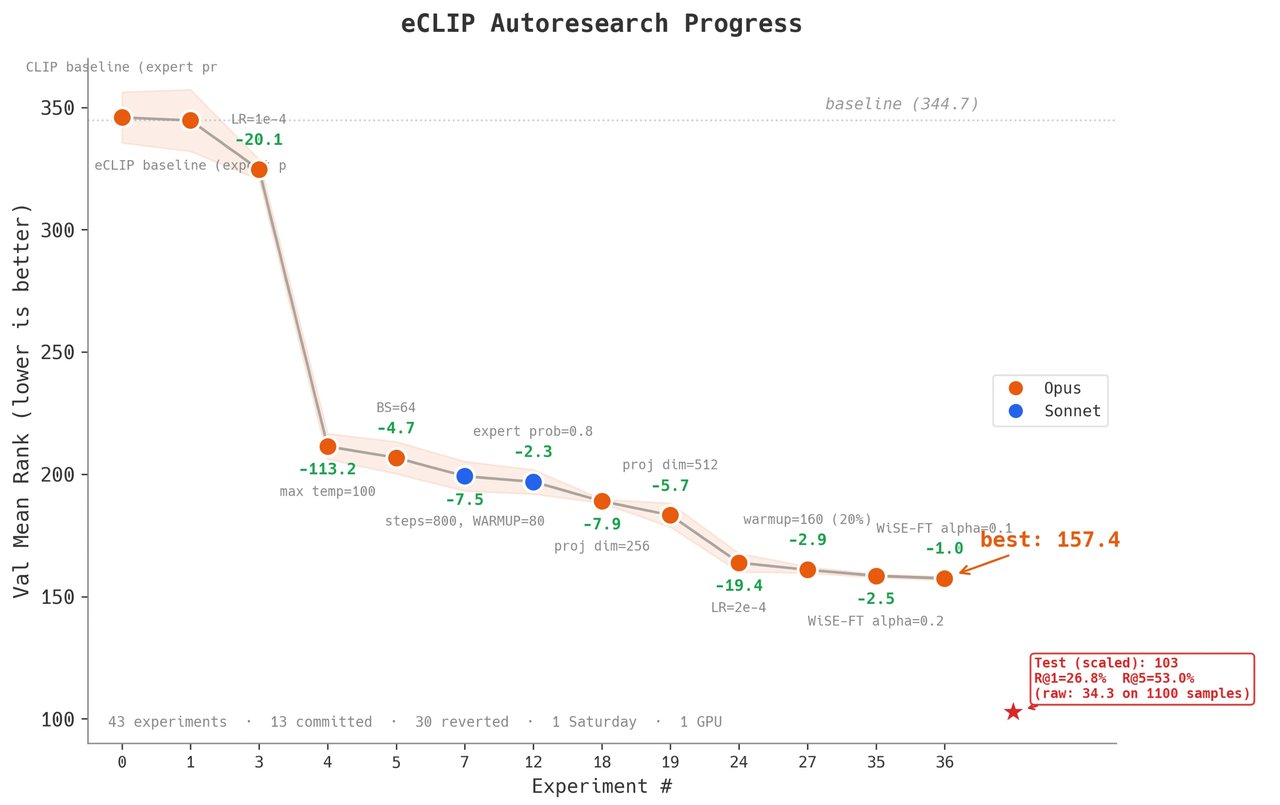
The numbers
- Before: Mean rank of 344.68 (higher = worse)
- After: Mean rank of 157.43 — a 54% improvement
- Final test accuracy: 53% for finding text from images, 51.4% for finding images from text
- Time spent: One day of automated experiments
- Human effort: Setting up the framework, then watching
Where AI excelled — and where it didn't
The most important finding isn't the numbers — it's what kind of work the AI was good at.
AI was great at: Structured optimization — tweaking settings, adjusting parameters, finding the right combination of existing techniques. Think of it like a tireless lab assistant who tries every possible dial position.
AI struggled with: Creative "moonshot" ideas — fundamentally rethinking the architecture or trying something completely new. The agent's ambitious experiments had high failure rates and diminishing returns.
This matches what many researchers are finding: AI agents are excellent at exploring a known search space but still can't replace the creative leaps that lead to breakthroughs.
Why this matters for you
You don't need to be a PhD researcher to take something from this story:
- If you have repetitive testing work — A/B testing marketing copy, optimizing ad spend, tuning spreadsheet formulas — AI agents can run dozens of variations while you do other things
- If you've shelved a project — autoresearch lets you revisit abandoned work without committing weeks of your own time
- If you use Claude Code — this same loop (try → test → keep or revert) is the core pattern behind productive AI-assisted coding
The key insight: AI is best when you give it a clear goal and a way to measure success. "Make this number go down" works. "Invent something nobody has thought of" doesn't — yet.
How autoresearch works under the hood
The setup is surprisingly simple. The AI agent gets:
- A training script it can modify
- A scratchpad file where it keeps notes on what it's tried
- A sandboxed environment (no internet access, no way to run dangerous code)
- Clear evaluation metrics to optimize
The framework runs in phases: first tuning basic settings (hyperparameters), then trying structural changes, then attempting creative experiments. Each phase builds on what worked before.
If you want to try something similar with your own projects, Karpathy's original autoresearch post explains the setup, and you can use Claude Code as the agent with a similar configuration.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments