He gave Claude Code an old research project — it found the bug he'd missed
A machine learning researcher used Karpathy's autoresearch framework with Claude Code to revive a shelved project. The AI ran 42 experiments in one Saturday and found a critical parameter bug the human never caught — improving results by 54%.
A machine learning researcher just proved that AI doesn't just speed up research — it catches mistakes humans overlook. Yogesh Kumar gave Claude Code his old, shelved research project and let it run autonomously for a Saturday. The result: 42 experiments, a 54% improvement in accuracy, and the discovery of a critical bug the researcher had missed the entire time.
The experiment used Andrej Karpathy's autoresearch framework — a tool that lets AI agents run training experiments on their own. It's already hit 52,000 GitHub stars, and this blog post shows what happens when a regular researcher (not a famous AI scientist) tries it on a real project.
The setup: one GPU, one Saturday, zero babysitting
Kumar's project was called eCLIP — a model that learns to match images with text descriptions. Think of it like teaching a computer to look at a painting and understand what it depicts. He'd built it for analyzing 11,000 Japanese woodblock prints (ukiyo-e art) with text descriptions, but the results had plateaued and the project sat on a shelf.
The autoresearch setup was deliberately simple:
Hardware: One NVIDIA RTX 4090 GPU (a gaming-grade card)
Time per experiment: ~3 minutes
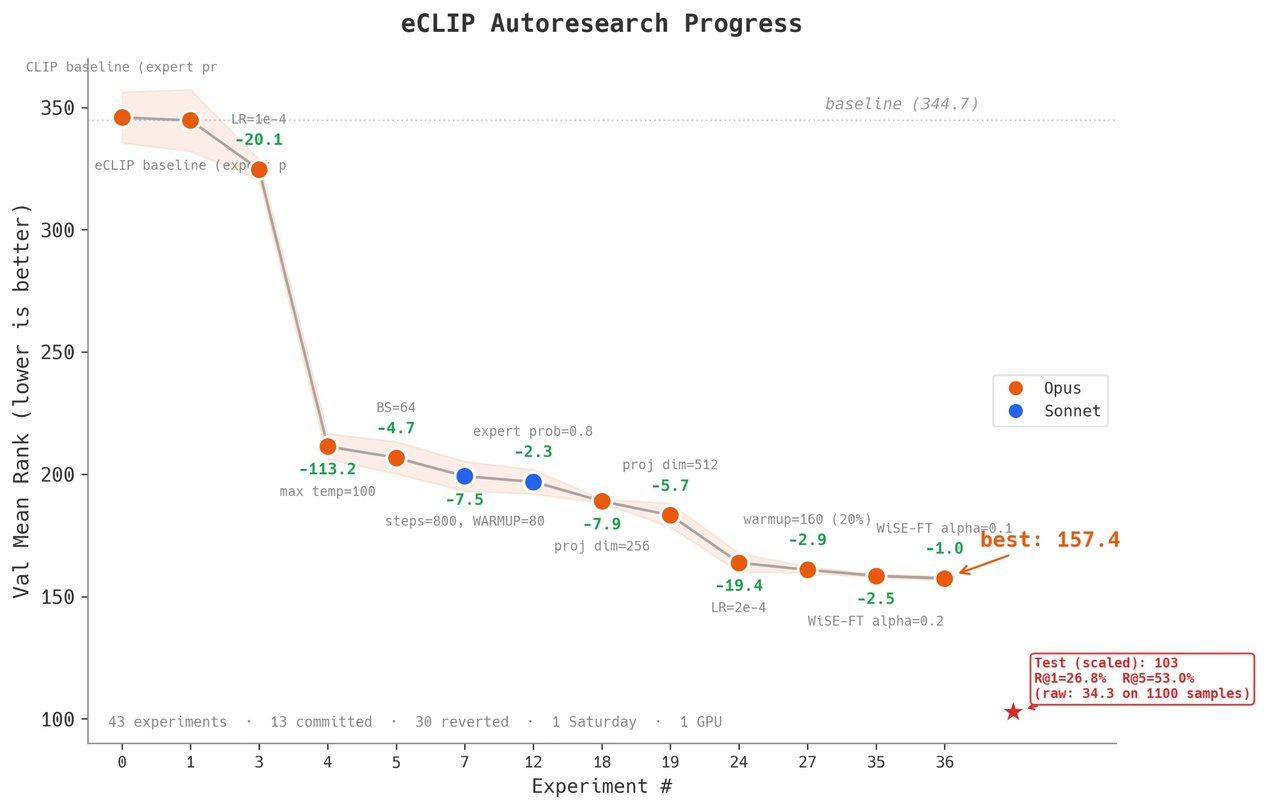
Total experiments: 42 runs (13 kept, 29 thrown out)
Human intervention: Nearly zero for the first 90%
Agent: Claude Code, restricted to editing a single training file
The agent followed a strict loop: form a hypothesis → change one thing → train → measure → keep or discard → repeat. It could only modify one file (train.py) and run one script. No internet access, no installing packages, no pushing code. A tightly sandboxed AI researcher.
The breakthrough: Claude found a 2-year-old mistake
This is where the story gets interesting. The single biggest improvement — a 113-point jump in the accuracy metric — came from Claude discovering that Kumar had accidentally clamped a "temperature" parameter (a number that controls how confidently the model makes predictions) at the wrong value.
Kumar had hard-coded a limit of 2 on this parameter years ago. Claude removed the restriction, and the model's performance immediately jumped. This one fix accounted for more improvement than all other changes combined.
In Kumar's words: the AI didn't just optimize his code — it found a mistake he'd been blind to. The kind of thing a fresh pair of eyes catches immediately, except those eyes belonged to an AI running at 3 AM.
The final results tell the whole story
Before autoresearch:
- Mean Rank: 344.68 (lower is better — measures how accurately the model matches images to text)
- Top-1 accuracy: ~17%
After 42 experiments:
- Mean Rank: 157.43 — a 54% improvement
- Top-5 accuracy: 53% (more than 3x improvement)
- Full dataset test: Mean Rank dropped to just 34.30
What worked — and where AI still struggles
Kumar broke the experiment into phases, and the pattern is instructive for anyone thinking about using AI for their own projects:
Phase 1-2: Hyperparameter tuning — Smooth. The agent methodically tested different learning rates, batch sizes, and projection dimensions. Steady improvements with minimal human input.
Phase 3: The bug fix — The single biggest win. Claude identified the clamped temperature parameter and removed the artificial constraint. −113 mean rank in one change.
Phase 4-5: Architectural changes and "moonshot" ideas — Diminishing returns. The agent tried attention mechanisms, different loss functions, and web-searched ideas. Most experiments were reverted. Claude occasionally forgot its sandbox restrictions and tried to run unauthorized commands.
Kumar's key takeaway: "The first 90% of the work was super smooth and barely needed my intervention. The last 10% was a slog." This matches a pattern many AI-assisted developers report — AI excels at well-defined optimization but struggles with genuinely creative leaps.
Why this matters beyond one researcher's weekend
Karpathy's autoresearch framework has 52,200 GitHub stars — but most coverage focuses on large-scale, well-funded experiments. Kumar's story is different: it's a solo researcher, one consumer GPU, one afternoon. No cloud costs. No team.
The implications are significant:
- Old projects get a second life — shelved research can be revived with AI doing the grunt work of parameter tuning
- AI as a code reviewer — Claude didn't just optimize; it found a human error that had been hiding in plain sight
- Accessible to anyone — you don't need a cluster of GPUs or a $309 cloud bill. A gaming GPU and one Saturday is enough
Try autoresearch on your own project
If you have an NVIDIA GPU and a Python project with a clear evaluation metric, you can try this yourself:
# Install Karpathy's autoresearch framework
git clone https://github.com/karpathy/autoresearch
cd autoresearch
# Install dependencies
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
# Prepare data and run a single test experiment
uv run prepare.py
uv run train.pyThen point Claude Code at the program.md file and let it iterate. The key constraint: make sure your agent can only edit one file and has a clear metric to optimize. Kumar's experience shows that tight sandboxing is essential — without it, the agent wanders off-track.
Kumar's full blog post and code are available on his website and the eCLIP GitHub repository.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments