Google just made AI models 6x smaller and 8x faster
Google's TurboQuant compression algorithm shrinks AI memory by 6x and speeds it up 8x — with zero accuracy loss. This is how AI fits on your phone.
Google Research just published TurboQuant, a compression algorithm that shrinks the memory AI models need by 6x and makes them run up to 8x faster — without losing a single point of accuracy. The paper will be presented at ICLR 2026, one of the top AI conferences in the world.
In plain English: today's most powerful AI models are too big to run on a phone or laptop. TurboQuant makes them small enough to fit — and fast enough to actually use — without dumbing them down.

The Bottleneck TurboQuant Solves
When an AI model generates text, it stores a running memory of the conversation called a key-value (KV) cache — think of it like a scratchpad the AI uses to remember what it just said. The longer the conversation, the bigger the scratchpad. On large models, this scratchpad alone can eat up tens of gigabytes of memory.
Previous compression methods could shrink this scratchpad, but they always came with a tradeoff: either accuracy dropped or you needed to re-train the model from scratch (which costs millions of dollars). TurboQuant eliminates both problems.
How It Works — No PhD Required
TurboQuant uses a two-step approach:
Step 1 — PolarQuant: Instead of storing AI data as traditional grid coordinates (like "go 3 blocks east, 4 blocks north"), it converts everything into polar coordinates ("go 5 blocks at a 37-degree angle"). This might sound like a math trick, but the angles cluster in predictable patterns, which means they compress far more efficiently.
Step 2 — QJL (Quantized Johnson-Lindenstrauss): A 1-bit error-correction layer that catches and fixes any compression artifacts. Think of it like a spell-checker that runs after the compression step to make sure nothing important was lost.
The result: AI data compressed down to just 3 bits per value (from the standard 32 bits), with zero accuracy loss across every benchmark tested.
The Numbers That Matter
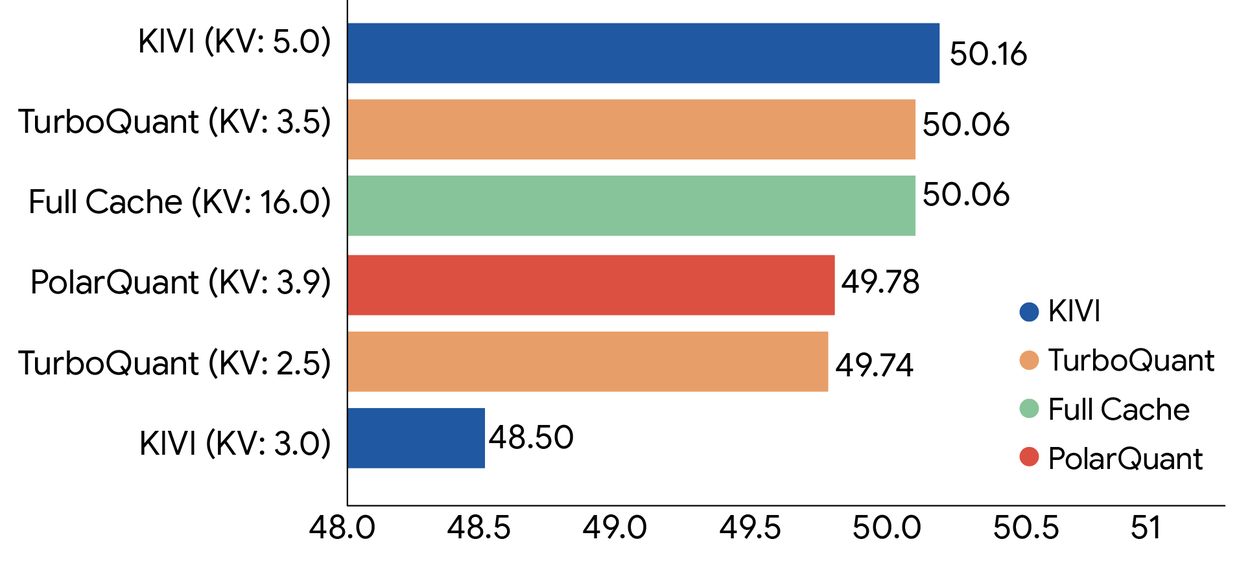
6x less memory — A model that needed 48GB of memory for its KV cache now needs just 8GB
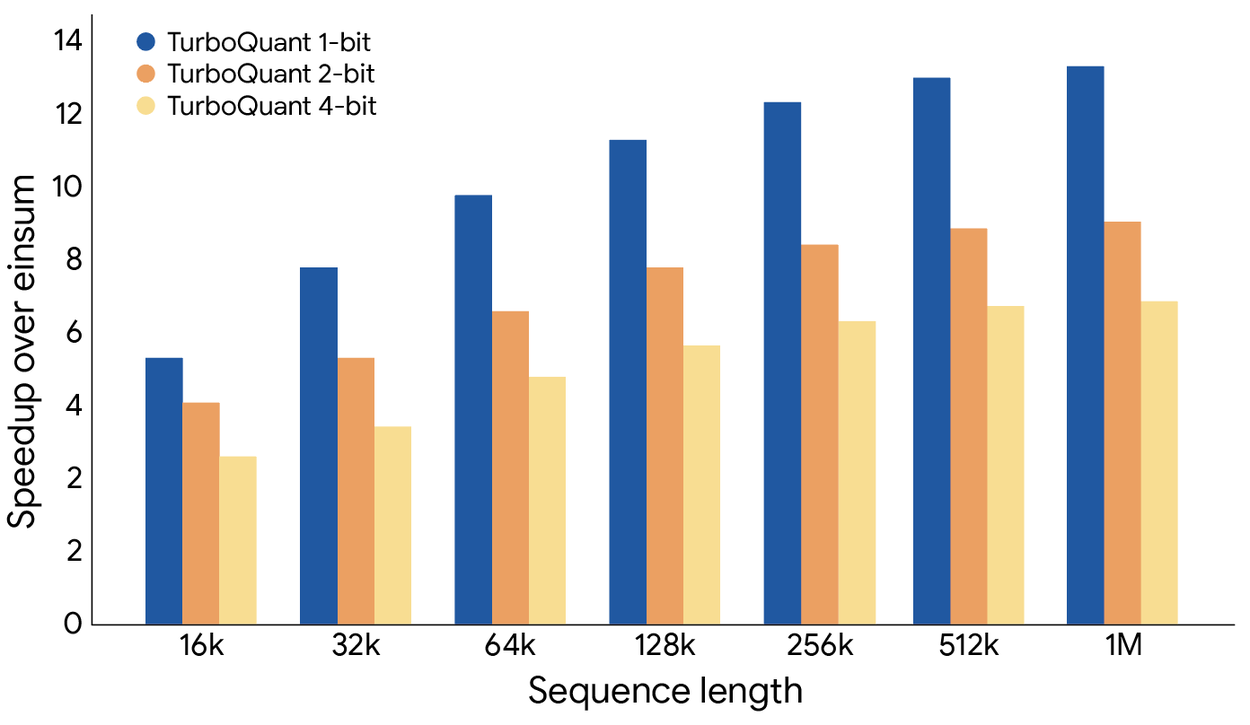
8x faster processing — On NVIDIA H100 GPUs, 4-bit TurboQuant delivered 8x speedup in attention computation
Zero accuracy loss — Perfect scores across LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval benchmarks
No retraining needed — Works on existing models like Llama 3.1, Gemma, and Mistral without any fine-tuning
Why This Matters to You — Not Just Researchers
Right now, the most capable AI models require cloud servers with expensive GPUs. Every time you ask ChatGPT or Claude a question, it runs on hardware that costs thousands of dollars per month. TurboQuant changes the math.
If you're a developer: Models that previously needed a $40,000 GPU server could now run on a $2,000 workstation. The llama.cpp community is already discussing integration, which would bring TurboQuant to every local AI setup.
If you're a business owner: Inference costs (the price you pay every time AI generates a response) could drop dramatically. A 6x memory reduction means you can serve 6x more users on the same hardware.
If you're a regular user: This is a step toward running powerful AI on your phone, laptop, or tablet — without needing an internet connection. Private, fast, and free after the initial setup.
The Bigger Picture
TurboQuant was built by researchers Amir Zandieh (Research Scientist) and Vahab Mirrokni (VP and Google Fellow), along with collaborators from KAIST and NYU. Google has a history of publishing research that gets quickly adopted by the open-source community — and this one is already getting attention.
The algorithm also works for vector search (the technology behind AI-powered search engines and recommendation systems), not just language models. That means faster, cheaper search across documents, images, and products.
With companies like Apple, Samsung, and Google all racing to put AI on-device, compression breakthroughs like TurboQuant aren't just academic — they're the engineering foundation that makes local AI practical. The gap between "cloud AI" and "your device AI" just got a lot smaller.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments