Mistral just dropped a free voice AI that beats ElevenLabs
Mistral's new Voxtral TTS is an open-weight text-to-speech model that runs on your phone, clones voices in 5 seconds, and beat ElevenLabs 63% of the time in blind tests.
French AI company Mistral just released Voxtral TTS — the first frontier-quality, open-weight text-to-speech model designed for enterprise use. In blind listening tests, human evaluators preferred Voxtral TTS over ElevenLabs Flash v2.5 roughly 63% of the time. On voice customization tasks, that number jumped to nearly 70%. And Mistral is giving away the full model weights for free.
The model runs on a smartphone, a laptop, or even a smartwatch. It needs just 3GB of RAM when compressed. Time-to-first-audio is 90 milliseconds, and it generates speech at 6x real-time speed — meaning a 60-second clip takes about 10 seconds to produce. It supports 9 languages: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
Clone any voice with 5 seconds of audio
Voxtral TTS can replicate a custom voice from less than 5 seconds of audio. It captures accents, inflections, intonations, and even speech irregularities. When switching between languages, the cloned voice keeps its characteristics — useful for dubbing, podcast localization, or building multilingual voice assistants.
Mistral claims the model performs at parity with ElevenLabs v3 — that's ElevenLabs' premium, higher-latency tier — on emotional expressiveness. But Voxtral TTS matches the latency of the much faster Flash model. In plain terms: it sounds as good as the expensive option, but responds as fast as the cheap one.
Three brains in one model
The architecture has three pieces working together:
3.4 billion parameter transformer decoder — the main brain that understands text and decides how to say it (built on Ministral 3B, Mistral's edge-focused language model)
390 million parameter flow-matching acoustic transformer — converts the text understanding into a natural-sounding voice pattern (think of it as the "vocal cord" that shapes how words actually sound)
300 million parameter neural audio codec — Mistral's custom-built audio compressor that turns the voice pattern into actual audio you can hear, developed entirely in-house
Total: roughly 4.1 billion parameters. That's about 3x smaller than what Mistral calls the industry standard for comparable quality. Smaller means it can run on devices ElevenLabs can't touch — like wearables and low-end phones.
Who this actually helps
If you're building a voice assistant or chatbot: You can now run production-quality text-to-speech entirely on your own servers. No per-word API fees, no data leaving your network. Mistral says Voxtral TTS supports GDPR and HIPAA-compliant deployments through on-premise or private cloud setups.
If you're a content creator or podcaster: Voice cloning from a 5-second sample opens up multilingual dubbing, audiobook narration, and voice-over work without expensive studio sessions or per-minute fees.
If you're a developer exploring voice AI: The open weights mean you can fine-tune, modify, and deploy without licensing headaches. This is a genuine alternative to ElevenLabs' $5-99/month subscription tiers.
The full voice pipeline is now complete
Voxtral TTS is the final piece of a pipeline Mistral has been assembling since July 2025:
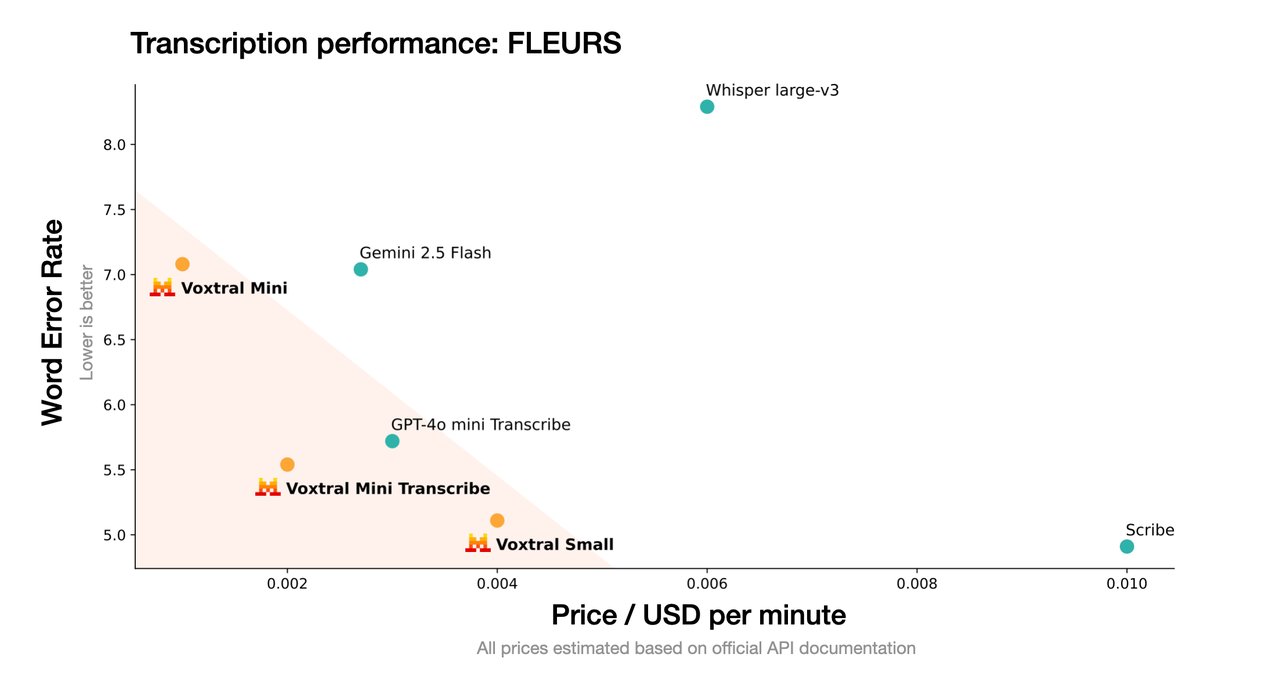
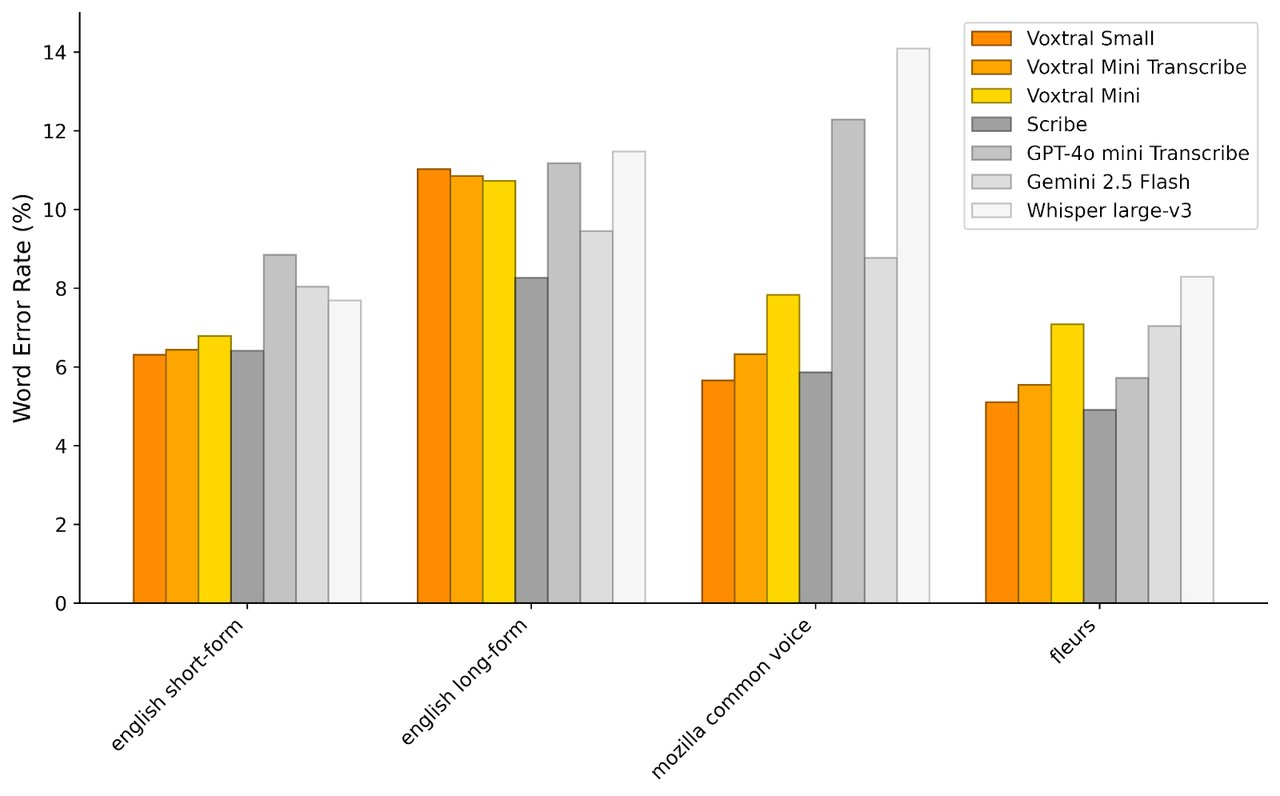
• Voxtral Transcribe — converts speech to text ($0.003/minute, 13 languages, 4% word error rate)
• Voxtral Realtime — live transcription with sub-200ms latency (open-weight, Apache 2.0)
• Voxtral TTS — converts text back to natural speech (today's release)
• Mistral language models — the reasoning layer in between
• Forge — lets enterprises customize any of these models on their own data
This means a company can now build a complete voice AI system — listen, understand, respond in natural speech — using only Mistral models. No ElevenLabs for TTS, no Deepgram for transcription, no OpenAI for reasoning. One vendor, fully open-weight, running on your hardware.
How to try it
Voxtral TTS is available through Mistral's API today. You can also download the open weights from Hugging Face to run locally. For the full Voxtral family, check the official Voxtral page.
If you want to test the speech-to-text side, Mistral has a live audio playground that supports files up to 1GB in .mp3, .wav, .m4a, .flac, and .ogg formats.
For local deployment, the Voxtral Realtime model (speech-to-text) can be installed via vLLM:
pip install -U vllm soxr librosa soundfile
pip install --upgrade transformers
# Launch the server
vllm serve mistralai/Voxtral-Mini-4B-Realtime-2602ElevenLabs should be worried
ElevenLabs has been the dominant name in AI voice generation since 2023. Their v3 model is widely considered the gold standard for emotionally nuanced speech. But they charge $5 to $99/month for API access, and audio data passes through their servers.
Voxtral TTS matches v3 quality on expressiveness while being fully self-hosted and free to use. For companies processing thousands of hours of audio — call centers, e-learning platforms, audiobook publishers — the cost difference is enormous.
The open-weight strategy also means community-driven improvements. Mistral's previous Voxtral Realtime model already has a pure C implementation, MLX Audio support for Apple Silicon, and a Rust implementation. Expect similar community momentum around the TTS model.

Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments