Cohere Transcribe just beat Whisper by 27% — it's free
Cohere's new open-source speech recognition model ranks #1 on the global leaderboard, beats OpenAI Whisper by 27%, supports 14 languages, and runs on a $200 GPU.
If you've ever struggled with bad transcriptions — garbled meeting notes, wrong names, missing sentences — there's a new option that just claimed the top spot on the world's most competitive speech recognition leaderboard. Cohere Transcribe is an open-source model that converts speech to text more accurately than anything else available, including OpenAI's Whisper.
The numbers speak for themselves: 5.42% average word error rate versus Whisper's 7.44% — a 27% improvement. It scored #1 on HuggingFace's Open ASR Leaderboard, beating NVIDIA, IBM, Zoom, and ElevenLabs. And it's completely free under the Apache 2.0 license.
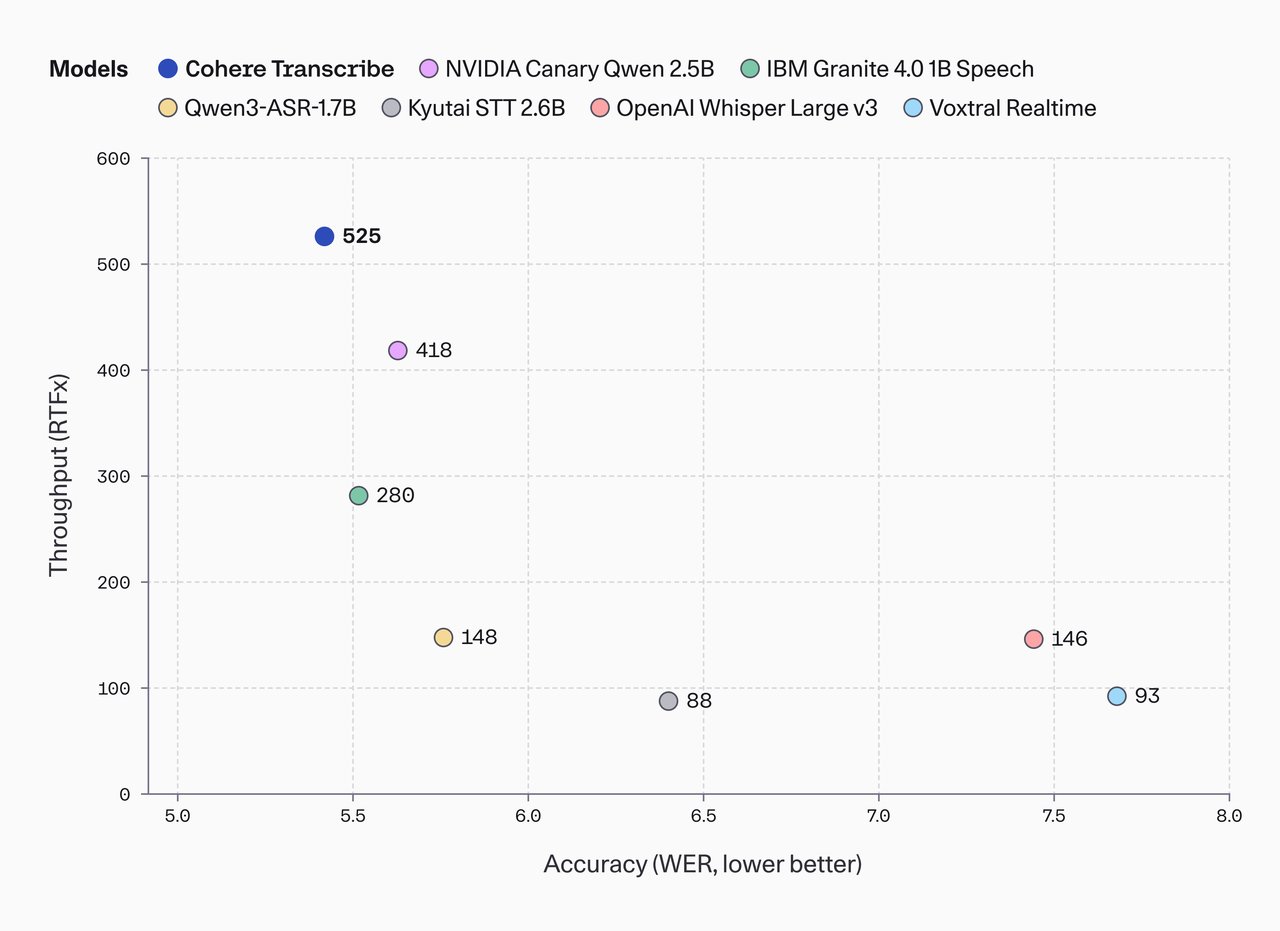
Why it matters beyond the benchmarks
Speech-to-text (turning spoken words into written text) sounds simple, but getting it right at scale has been one of AI's hardest problems. Meeting notes with wrong names, medical transcriptions that miss critical words, podcast transcripts that garble technical terms — these errors cost real time and money.
Cohere Transcribe doesn't just beat competitors on standard tests. In human evaluations, where real people judged transcription quality for accuracy, coherence, and minimal hallucination (making up words that weren't spoken), it won 61% of head-to-head comparisons against every other model.
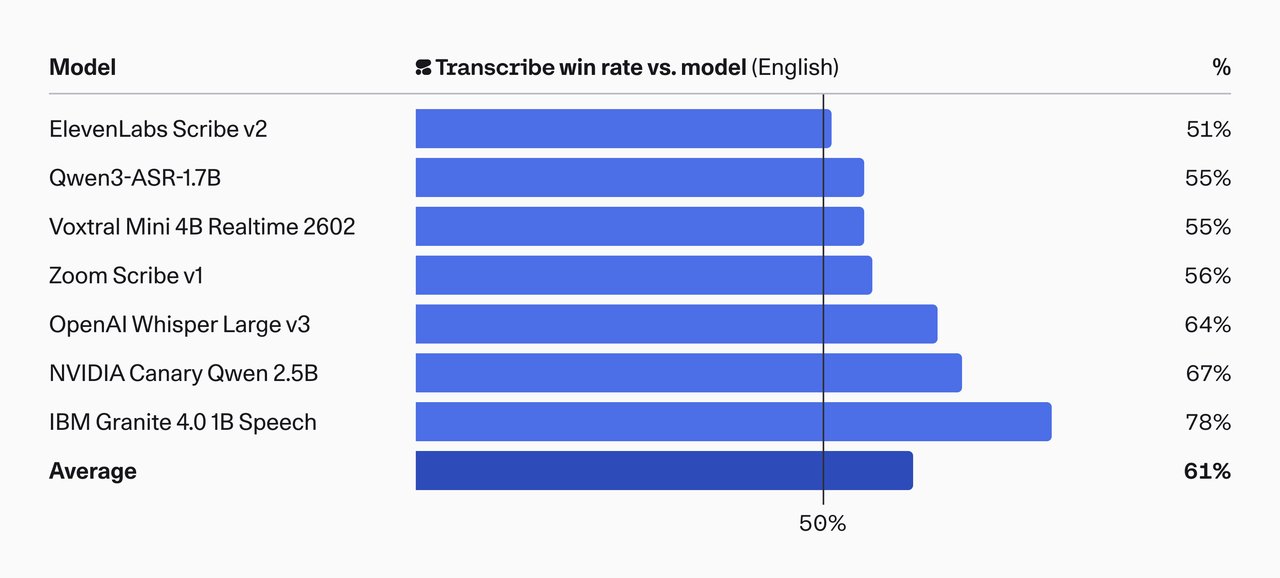
14 languages, one model, runs on a basic GPU
The model supports 14 languages: English, French, German, Spanish, Portuguese, Italian, Dutch, Polish, Greek, Arabic, Chinese, Japanese, Korean, and Vietnamese. It ranked 2nd among all open-source models on the multilingual leaderboard.
At 2 billion parameters (a measure of model complexity), it needs roughly 4 GB of video memory to run — meaning it works on consumer GPUs like the NVIDIA RTX 3060 or RTX 4060. No data center required. It also processes audio up to 3x faster than comparable models in its size class.
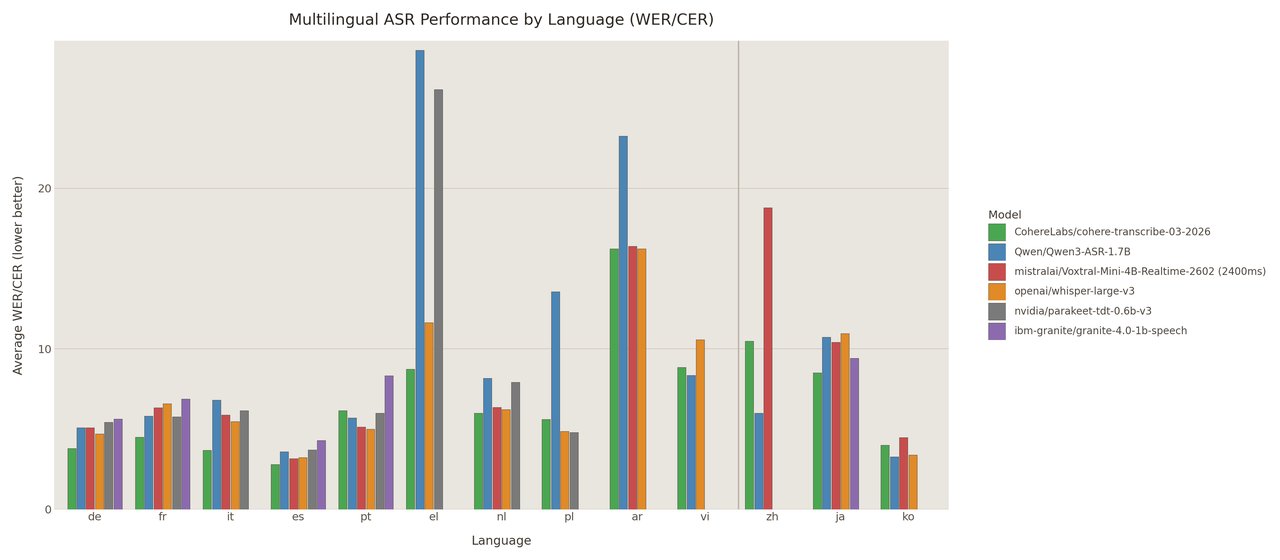
The leaderboard in context
| Model | Avg Error Rate | License |
|---|---|---|
| Cohere Transcribe (2B) | 5.42% | Apache 2.0 (free) |
| Zoom Scribe v1 | 5.47% | Proprietary |
| IBM Granite 4.0 Speech | 5.52% | Apache 2.0 |
| NVIDIA Canary Qwen | 5.63% | Proprietary |
| ElevenLabs Scribe v2 | 5.83% | Proprietary |
| OpenAI Whisper Large v3 | 7.44% | MIT (free) |
Who should care — and what you can actually do
Content creators and podcasters: Transcribe interviews and episodes more accurately than Whisper, with proper punctuation, for free. No cloud API needed — run it on your own machine.
Businesses with meetings: If you're self-hosting transcription (to keep conversations private), this replaces Whisper with measurably better accuracy — especially for names and technical terms.
Developers building voice features: Drop it into your app via HuggingFace Transformers or serve it production-ready with vLLM (a fast model server). Also available as a free API at Cohere's dashboard with rate limits.
Try it right now
Install and run it on your machine with Python:
pip install "transformers>=4.56" torch huggingface_hub soundfile librosa sentencepiece protobufThen transcribe an audio file in just a few lines:
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
import torch
model_id = "CohereLabs/cohere-transcribe-03-2026"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, trust_remote_code=True).to("cuda")
texts = model.transcribe(processor=processor, audio_files=["meeting.wav"], language="en")
print(texts[0])Or try it instantly in the browser via the HuggingFace demo — no install needed.
What it can't do (yet)
Cohere Transcribe doesn't automatically detect which language is being spoken — you have to specify it. It also can't identify different speakers in a conversation (no speaker diarization) or give you word-level timestamps. And like most speech models, it can hallucinate (invent words) on silent or noisy audio, so Cohere recommends pairing it with a voice activity detector for production use.
These are real limitations, but they're standard for the current generation of speech models. The core job — turning spoken words into accurate text — is where Cohere Transcribe now leads the world.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments