NVIDIA's free 120B model just outpaced GPT-4o
NVIDIA just released Nemotron 3 Super 120B — open, free, 5x faster than its predecessor, and #1 on DeepResearch Bench beating all closed AI.
NVIDIA just turned the AI world upside down — again. On March 11, 2026, the chipmaker dropped Nemotron 3 Super 120B, a fully open-weight model (free to download and use commercially) that outperforms every open AI model in its class and beats all closed-source competitors on DeepResearch Bench — while being completely free to access via OpenRouter.
The headline number hides the trick: 120 billion total parameters, but only 12 billion are active at any given moment. This is possible via a LatentMoE architecture (Latent Mixture-of-Experts — a system where only a small specialized slice of the AI activates per task, like calling in the right specialist instead of flying in the whole team). The result: frontier intelligence at a fraction of the compute cost.
The Architecture Trick That Makes This Possible
Nemotron 3 Super is the first major AI model to combine three entirely different design philosophies into one: Mamba layers (a newer type of memory processing that handles long text sequences more efficiently than traditional attention), standard Transformer attention (the architecture behind ChatGPT and most modern AI), and LatentMoE routing (where only relevant specialist sub-networks activate per query, keeping costs low without sacrificing quality). NVIDIA calls this a "hybrid" architecture — and the efficiency gains are remarkable.
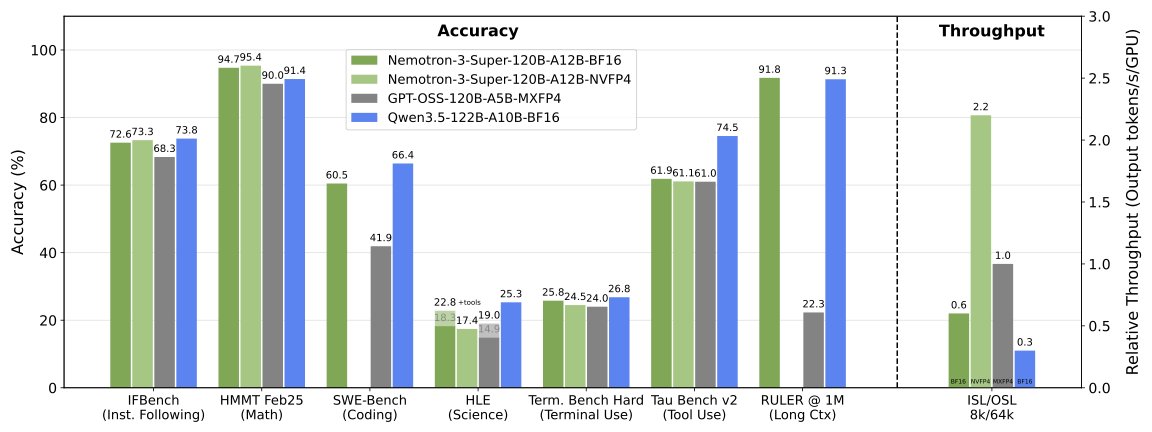
The key speed figure: 5× higher throughput (responses generated per second) than the previous Nemotron Super model, and 2.2× higher throughput than GPT-OSS-120B — a comparable dense model of the same total size. Against Qwen3.5-122B (Alibaba's competing 122B model), Nemotron runs 7.5× faster under identical hardware conditions. On NVIDIA's newest Blackwell B200 chips with NVFP4 precision, the speed advantage reaches 4× faster than a standard H100 GPU.
The context window is the other headline: 1 million tokens of working memory (roughly 750,000 words — the equivalent of 10 full novels in a single session). Critically, it maintains 96%+ accuracy on RULER-500 (a standardized benchmark that tests whether an AI truly retains and uses information across long documents, not just appears to) at both 256K and 512K context lengths — something most "1M token" models quietly fail at when tested.
• 120B total parameters → only 12B active per query (10× efficiency ratio)
• First hybrid Mamba + Transformer + LatentMoE design at this scale
• Native 1 million token context window
• Memory accuracy at 256K context (RULER-500): 96.52%
• Memory accuracy at 512K context (RULER-500): 96.23%
• On Blackwell B200 vs. H100 FP8 baseline: 4× speed improvement
• Multi-Token Prediction (MTP) layers give additional 3× wall-clock speedup on structured generation
Benchmark Scores vs. Every Major Competitor
Raw benchmark results for anyone evaluating whether to switch from paid closed models to this open alternative:
- PinchBench: 85.6% — best open model in its class; tests real-world multi-step agentic reasoning (chained AI tasks where the AI must plan and act autonomously across multiple steps)
- LiveCodeBench v6: 78.44% — real coding ability on challenges published after the training cutoff, preventing the AI from "remembering" pre-memorized answers
- GPQA: 79.42% — graduate-level science questions written by PhD experts specifically designed to stump current AI systems
- MMLU-Pro: 83.33% — multi-domain professional knowledge covering law, medicine, STEM, finance, and humanities
- HMMT Feb25 (with tools): 95.36% — Harvard-MIT Math Tournament problems, one of the most rigorous math benchmarks in current AI evaluation
- Arena-Hard-V2: 76.00 — head-to-head user preference ratings against other top models in live comparisons
- TauBench V2: 60.46 — tool-use and agentic task completion, measuring real-world usefulness in automated workflows
- DeepResearch Bench I & II: #1 globally — NVIDIA's AI-Q research agent, powered by Nemotron 3 Super, tops both leaderboards, beating ChatGPT, Claude, and Gemini on complex multi-source research tasks
That last result matters most for everyday professionals. Deep research tasks — searching multiple sources, reasoning through conflicting information, synthesizing a coherent answer — are exactly what people pay $20/month for with ChatGPT Plus or Perplexity Pro. Nemotron 3 Super outperforms both on standardized benchmarks, and the base model is free.

Seven Enterprise Giants Already Using It
NVIDIA launched Nemotron 3 Super with confirmed production deployments from day one — not a research preview, not a waitlist.
- Perplexity — integrating into their AI-powered search pipeline (the engine behind Perplexity's real-time answers)
- CodeRabbit — AI code review that automatically scans pull requests (new code submissions from developers) for bugs, security holes, and improvement suggestions
- Factory — autonomous software engineering agents that write and ship production code without human review
- Palantir — enterprise data intelligence and U.S. government AI infrastructure
- Amdocs — telecom industry AI automation at global carrier scale
- Cadence — chip design software and semiconductor AI workflows
- Siemens — industrial automation and manufacturing AI
The model is live on 15+ deployment platforms including Google Cloud Vertex AI, Oracle OCI, Hugging Face, and OpenRouter — meaning teams can plug it into existing infrastructure without migrating or rebuilding pipelines from scratch.
How to Try It Right Now — From Free to $0.20/1M Tokens
Option 1: OpenRouter Free Tier (zero setup, browser-based, no payment required)
Visit OpenRouter's free Nemotron 3 Super endpoint and start chatting immediately. No GPU, no API key, no cost.
Option 2: Ollama (local installation, one command)
ollama run nemotron-3-superOption 3: vLLM for Production (requires minimum 2× H100-80GB GPUs)
pip install vllm==0.17.1
export MODEL_CKPT=nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-FP8
vllm serve $MODEL_CKPT \
--served-model-name nvidia/nemotron-3-super \
--dtype auto --kv-cache-dtype fp8 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--enable-expert-parallel \
--reasoning-parser nemotron_v3Option 4: NVIDIA NIM API (cloud-hosted, free trial available at NVIDIA NIM)
curl https://integrate.api.nvidia.com/v1/chat/completions \
-H "Authorization: Bearer $NVAPI_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"nvidia/nemotron-3-super","messages":[{"role":"user","content":"Write a Python web scraper"}]}'Paid API pricing through third-party cloud providers: $0.20 per million input tokens / $0.80 per million output tokens via Bitdeer, CoreWeave, and Vultr. For context: Claude Sonnet 3.7 is priced at $3.00/$15.00 per million tokens — making Nemotron 3 Super approximately 15–19× cheaper for high-volume deployments. At those rates, a team spending $1,000/month on AI API costs could get equivalent throughput for $53–67.
The Training Depth Behind the Performance
NVIDIA didn't just release model weights. They published training data, RL environments, and full training recipes alongside the model — a level of transparency that is extremely rare at this scale.
- 25+ trillion pretraining tokens processed during training (a volume comparable to the entire curated written internet)
- 10 trillion tokens from the training corpus released open-source for independent research and reproduction
- 7 million supervised fine-tuning samples drawn from a 40-million-sample pool — fine-tuning being the process of teaching a trained model to follow instructions helpfully, rather than just predicting the next word
- 1.2 million+ reinforcement learning trajectories across 21 task categories — structured practice runs where the model improved through automated trial-and-error feedback loops
- 153 total training datasets combined across domains and languages
- 43 programming languages and 20 natural languages represented in training
- 15 open RL training environments published so any team can reproduce or extend NVIDIA's training methodology
Most frontier AI companies release only model weights and a benchmark table. NVIDIA released the full training recipe, 10 trillion tokens of data, and the reinforcement learning environments — making independent verification, research extensions, and competitive comparisons possible in a way they haven't been before.
Developers building AI agents: The 1M token context and DeepResearch Bench #1 ranking make this the best open option for research synthesis, long document analysis, and multi-step autonomous workflows where current models lose track.
Cost-conscious teams: At $0.20/1M tokens vs. $3–15/1M for leading closed models, high-volume workloads can cut API spend by 15–75×. A $1,000/month budget becomes an $53–67/month budget for equivalent output.
AI researchers: 15 published RL environments and 10T tokens of open training data make this the most transparent frontier model released to date — reproducible results are now possible.
Self-hosted enterprises: Minimum hardware is 2× H100-80GB GPUs; NVFP4 on Blackwell B200 hardware delivers 4× the speed of H100 for on-premises inference.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments