Tencent's free voice AI talks and listens at the same time
Covo-Audio is a free 7B voice model that processes speech in real time — no cloud fees. It beats models twice its size on audio benchmarks.
Tencent just released Covo-Audio, a 7-billion parameter voice AI model that can have real-time conversations — talking and listening simultaneously — and it's completely free to download and run. While OpenAI charges premium rates for its proprietary Realtime API, Tencent's model is open source and available on both GitHub and HuggingFace.
What makes this different from a typical voice assistant: Covo-Audio doesn't need separate tools for hearing, thinking, and speaking. It processes everything — understanding your words, reasoning about them, and generating a spoken response — in one single system. That means less delay and more natural conversation flow.
One model, three ways to talk
Tencent released three variants, each built for a different use case:
Covo-Audio — The foundation model for researchers to build on
Covo-Audio-Chat — Fine-tuned for back-and-forth dialogue
Covo-Audio-Chat-FD — Full-duplex mode: talks and listens at the same time, like a real phone call
The full-duplex variant is the standout. Most voice AIs work like walkie-talkies — you talk, they listen, then they respond. Covo-Audio-Chat-FD handles both directions at once. In testing, it managed turn-taking correctly 99.7% of the time, handled pauses at 97.6%, and even produced natural "mm-hmm" acknowledgments during conversation at 93.9% accuracy.
Punching above its weight on benchmarks
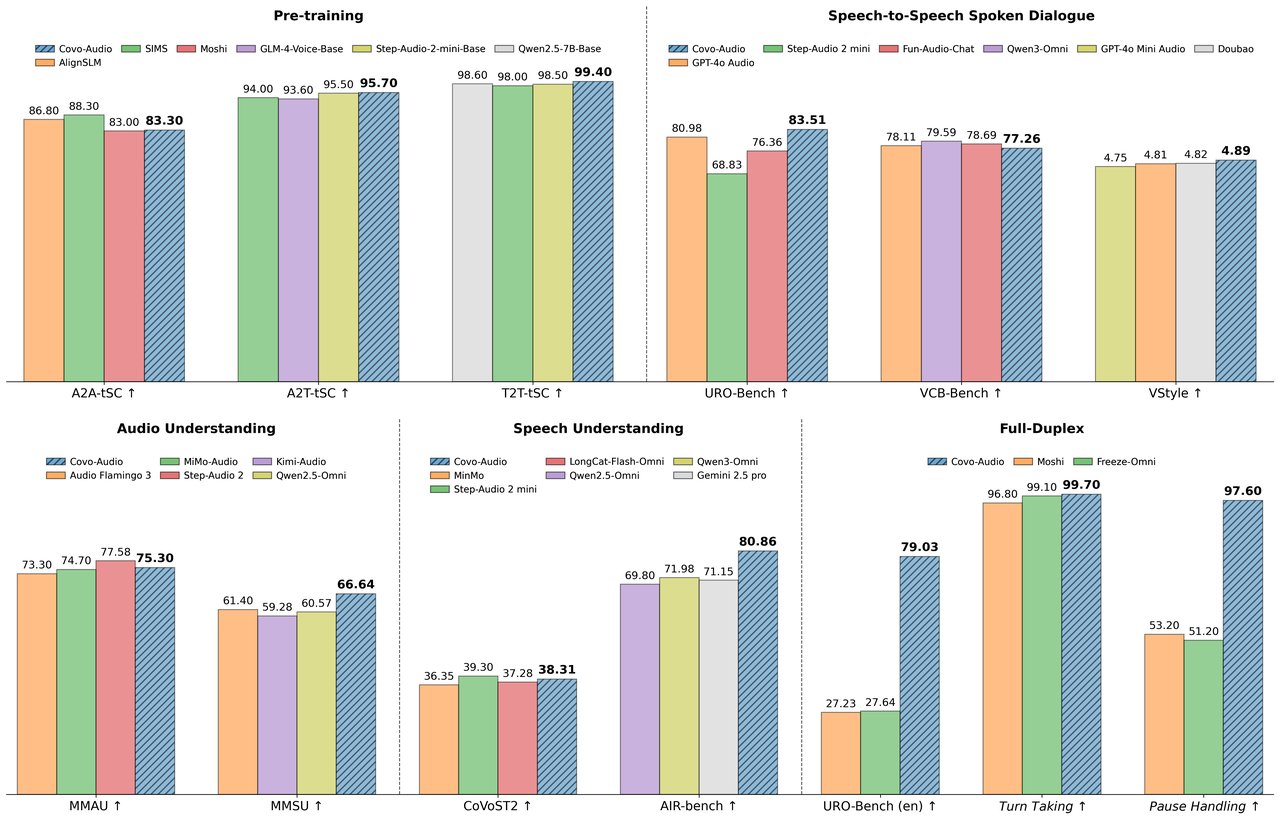
On the MMAU audio understanding benchmark (a standardized test measuring how well AI understands sounds, music, and speech), Covo-Audio scored 75.30% — beating Alibaba's Qwen2.5-Omni (71.50%) at the same 7B scale, and coming within 2.3 points of Step-Audio 2, a model four times larger at 32 billion parameters.
For speech recognition (turning spoken words into text), it achieved a word error rate of just 4.71 on average — with standout scores of 1.45 on clean recordings. It also handles translation between English and Chinese in both directions.
Swap the voice without retraining
One clever feature Tencent calls "intelligence-speaker decoupling": you can change the voice the AI speaks in without retraining the underlying model. Think of it like changing the actor while keeping the script. This opens the door to custom voice assistants, accessibility tools, or multilingual applications — all from the same base model.
Built on proven foundations
Under the hood, Covo-Audio combines two well-known AI components:
Brain: Qwen2.5-7B (Alibaba's language model, handles reasoning and text)
Ears: OpenAI's Whisper-large-v3 (the gold standard for speech recognition)
It then uses NVIDIA's BigVGAN to convert generated tokens back into high-quality 24kHz audio output. The combination means it inherits the strengths of battle-tested components while adding Tencent's novel tri-modal architecture on top.
Set it up in five minutes
If you have a capable GPU and Python installed, setup is straightforward:
conda create -n covoaudio python=3.11
conda activate covoaudio
git clone https://github.com/Tencent/Covo-Audio.git
cd Covo-Audio
pip install -r requirements.txt
pip install huggingface-hub
hf download tencent/Covo-Audio-Chat --local-dir ./covoaudio
bash example.shYou can also try a community-built demo on HuggingFace Spaces without installing anything. Currently supports English and Chinese.
The catch: still early days
A few important caveats. The model has only 67 GitHub stars and 196 HuggingFace downloads so far — it's brand new. Tencent hasn't published end-to-end latency numbers (the delay between you speaking and getting a response), which is critical for real conversations. And while some sources report a permissive CC BY 4.0 license, others note a custom Tencent research license — check the repository before using it commercially.
The full-duplex conversation quality benchmarks were also developed internally by Tencent, meaning independent validation is still pending.
Who should pay attention
If you're building voice products: This is the most capable open-source full-duplex voice model available right now. You can run it on your own servers with zero API costs.
If you're a researcher: The speaker decoupling architecture is genuinely novel — you can experiment with voice transfer and multilingual applications without retraining.
If you're paying for OpenAI's Realtime API: Covo-Audio offers a free alternative, though you'll need your own GPU infrastructure to run it. It won't replace a polished cloud API overnight, but for prototyping or internal tools, the price difference is hard to ignore.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments