Claude just unlocked 1M context — at no extra charge
Anthropic made Claude's 1M token context window GA for Opus 4.6 and Sonnet 4.6 at standard pricing — no surcharges, no special setup needed.
One window to hold an entire novel — now free of premium pricing
On March 13, 2026, Anthropic quietly made one of the most practical upgrades in its history: the 1 million token context window (the maximum amount of text an AI can read, process, and remember in a single conversation) is now generally available for Claude Opus 4.6 and Claude Sonnet 4.6 at standard pricing.
What does "generally available" mean? It means no special flags, no beta headers, no premium tier required. Requests over 200,000 tokens simply work automatically. And crucially — the price did not go up.
A token (roughly three-quarters of a word — so 1 million tokens equals about 750,000 words) is the basic unit of text that AI models process. One million tokens is roughly:
- About 75 full non-fiction books (avg. 200 pages each)
- 3,000 pages of text
- 110,000 lines of code
- 600 PDF documents or images in one session
What the pricing change actually means for you
Before March 13, using Claude with very long documents was expensive. Once a conversation exceeded 200,000 tokens (about 150,000 words), a premium long-context surcharge kicked in — effectively doubling your per-token costs. Sonnet input pricing jumped from $3 to $6 per million tokens; Opus from $5 to $10.
That surcharge is now completely gone for Opus 4.6 and Sonnet 4.6. A 900,000-token session is billed at the exact same rate as a 9,000-token session. There is no longer any pricing cliff or multiplier for large documents.
Current standard pricing (unchanged):
- Claude Opus 4.6 — $5 per million input tokens / $25 per million output tokens
- Claude Sonnet 4.6 — $3 per million input tokens / $15 per million output tokens
Anthropic also raised the media limit (the number of images or PDF pages you can include in a single request) from 100 to 600 — a 6x increase that opens up serious document processing workflows.
Performance at a million tokens: does it actually work?
A big context window is useless if the model loses track of what was said 800,000 tokens ago. Anthropic has put real numbers behind this.
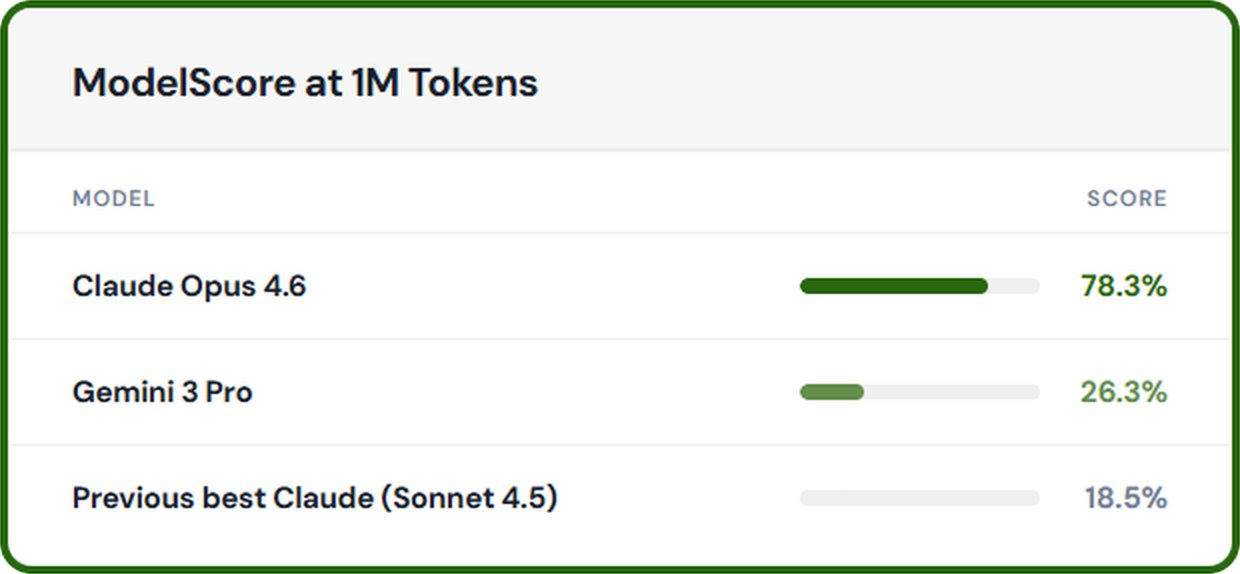
On the MRCR v2 benchmark (a test that measures how well a model can find two hidden facts buried inside a document the size of a small library), Claude Opus 4.6 scores 78.3% accuracy at the 1 million token length. That is the highest score among all frontier models at this context size. For comparison, Gemini 3 Pro scores 26.3% on the same test, and earlier Claude versions scored only around 18.5%.
Claude Sonnet 4.6 scores 68.4% on the related GraphWalks BFS benchmark. These are not just marketing numbers — they represent real improvements in how reliably the model can find, cross-reference, and reason about information spread across enormous documents.
Real-world examples: what can you actually do with 1M tokens?
Here are concrete ways that teams are already using the expanded window:
Developers and engineers: Load an entire codebase into Claude at once. No more switching between files, losing track of dependencies, or feeding the AI fragments. One engineer described the change: "Large diffs didn't fit in 200K context — loss of cross-file dependencies was eliminated with the expanded window." Cognition AI's Devin agent now processes entire pull requests in one pass.
Legal and compliance teams: Eve's litigation platform feeds complete case files into a single Claude session, allowing attorneys to track how contracts evolved across multiple rounds of negotiation without manually toggling between document versions. An entire legal case record — briefs, depositions, filings — fits comfortably.
Researchers and analysts: Future House, an AI research company, uses the expanded context to synthesize hundreds of academic papers and codebases simultaneously, accelerating scientific discovery. A researcher can now load 600 papers into one session and ask a single comprehensive question.
Marketers and content teams: Load an entire year of customer feedback, support tickets, and social media conversations into one Claude session. Ask it to find patterns, identify recurring complaints, or spot what topics are trending — without piecing together partial analyses from multiple truncated sessions.
Here is how to make a simple API call at this scale (no special setup required):
import anthropic
client = anthropic.Anthropic()
# No special headers needed — 1M context works automatically
# for Opus 4.6 and Sonnet 4.6
message = client.messages.create(
model="claude-opus-4-6-20260205",
max_tokens=4096,
messages=[
{
"role": "user",
"content": your_large_document_here # up to ~750,000 words
}
]
)
print(message.content)How Claude compares to competitors on context
Context window size and pricing together determine the true cost of working with large documents. Here is the current competitive picture:
- Claude Opus 4.6 & Sonnet 4.6 — 1M tokens, flat rate pricing, no surcharge
- GPT-4.1 (OpenAI) — 1M tokens, flat rate, but weaker long-context recall performance
- GPT-5.4 (OpenAI) — 256K token maximum, significantly higher per-token pricing
- Gemini 2.5 Pro (Google) — 1M token window, but still applies tiered pricing at scale
Claude is currently the only model family where both its two strongest tiers (Opus and Sonnet) offer 1M context at a flat, uniform rate.
Who gets it — and how to access it
Access depends on your plan:
API users (developers): Works automatically for Opus 4.6 and Sonnet 4.6. No beta header required. Your standard account rate limits apply across all context lengths — Anthropic also removed the separate dedicated 1M rate limits that previously existed.
Max, Team, and Enterprise users: The 1M window is active automatically for Opus 4.6. No extra charge, no settings to change.
Pro tier users: Access requires opting in. In Claude Code, type /extra-usage to enable the expanded context for your sessions.
The feature is also available on Claude Platform, Microsoft Foundry (Azure), and Google Cloud's Vertex AI — no code modifications required on any of these platforms.
Previously, working with very long documents required elaborate workarounds — breaking large files into chunks, summarizing sections to free up space, and stitching results back together manually. These workarounds were time-consuming, error-prone, and often introduced inaccuracies. Flat-rate 1M context eliminates all of that. As one engineer noted: "With 1M context, I search, re-search, aggregate edge cases, and propose fixes — all in one window."
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments