NVIDIA Custom AI Training Under 24 Hours: +26.7% Accuracy
Fine-tune a custom AI model in under 24 hours on one GPU — NVIDIA's free recipe delivers +26.7% accuracy gains. ServiceNow & IBM ship free tools too.
Three enterprise AI teams just dropped major open-source tools on Hugging Face in the same week — and the most surprising result came from NVIDIA: you can now build a custom AI search model in under 24 hours, with a single GPU, and see 26.7% accuracy gains on real company data. No PhD required. No $100K compute budget. Just a clear recipe anyone with cloud access can follow.
ServiceNow and IBM shipped their own frameworks the same week — one exposing a hidden flaw in how every voice AI is evaluated today, the other adding production-grade safety guardrails to IBM's open models. Together, these three releases signal something bigger: enterprise AI is moving past general chatbots and into specialized, measurable, production-hardened tools.
Custom AI Training Under 24 Hours: The Numbers Behind the Claim
NVIDIA's guide, published in partnership with Hugging Face on March 20, centers on a single headline claim: "With a single GPU and less than a day of training time, you can transform a general-purpose embedding model into one that truly understands your domain."
An embedding model (a tool that converts text into numbers so AI can compare and search documents) is the core of any AI-powered search or retrieval system. Generic, off-the-shelf embedding models struggle with specialized vocabularies: medical jargon, legal language, engineering datasheets. The fix used to require weeks of manual data labeling and massive GPU clusters.
The NVIDIA recipe collapses that into six stages, most taking under five minutes each:
- Stage 1: Synthetic data generation — AI generates training questions automatically from your documents (~1 hour, no manual labeling)
- Stage 2: Hard negative mining (~5 min) — hard negatives are documents that look relevant but contain the wrong answer, forcing the model to learn finer distinctions
- Stage 3: Fine-tuning the 1-billion-parameter base model (~1 hour on a single A100 GPU)
- Stage 4: BEIR evaluation (~5 min) — BEIR is a standardized test suite for information retrieval (document search) models
- Stage 5: Export to deployment format (ONNX/TensorRT, ~5 min)
- Stage 6: Production serving via NVIDIA NIM
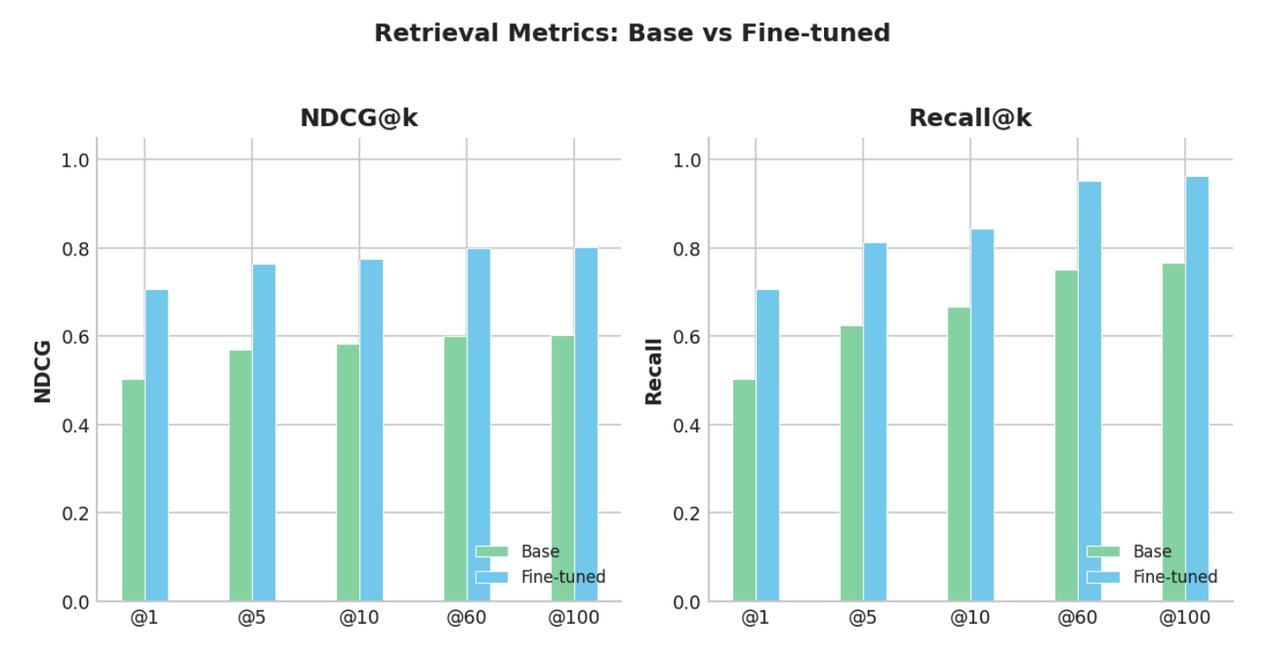
The base model is Llama-Nemotron-Embed-1B-v2 (a 1-billion parameter model built on Meta's Llama architecture, specialized for text search). After fine-tuning on NVIDIA's internal documentation, retrieval quality improved by +10.9% on NDCG@10 — a standard metric where higher scores mean relevant documents appear closer to the top of search results. On an external test using Atlassian JIRA ticket data — real corporate documents NVIDIA had no hand in preparing — Recall@60 jumped from 0.751 to 0.951: a +26.7% improvement.
Cisco's IT team independently validated the recipe: their engineers confirmed that "embedding fine-tuning, combined with synthetic data generation, can deliver measurable accuracy gains within a short time frame." That external confirmation matters — it proves the recipe generalizes beyond NVIDIA's own data.
What Hardware Do You Need for Custom AI Training?
An NVIDIA A100 or H100 GPU with 80GB VRAM is required for the fine-tuning stage. Cloud providers (AWS, GCP, Azure) rent these for roughly $2–4 per hour. For a small document corpus, NVIDIA reports the full pipeline runs in 2–3 hours — putting the total compute cost under $20. The recipe is built on NeMo, NVIDIA's open-source AI training framework, and the full guide is free on Hugging Face.
# Install base dependencies
pip install nemo-toolkit[nlp]
# Full step-by-step recipe:
# https://huggingface.co/blog/nvidia/domain-specific-embedding-finetune
# Base model on Hugging Face:
# https://huggingface.co/nvidia/llama-nemotron-embed-1b-v2Voice AI's Hidden Flaw: Scoring Well at the Wrong Thing
While NVIDIA published its embedding recipe, ServiceNow's AI research team released EVA (Evaluating Voice Agents) — and its core finding is uncomfortable for anyone shipping voice AI today. After testing 20 systems across both open-source and proprietary architectures, the pattern was consistent: agents that scored highest on task completion gave users a measurably worse experience. And no existing benchmark was catching this tradeoff.
A voice agent that successfully rebooks your flight might still interrupt you mid-sentence, repeat itself three times, and mispronounce the confirmation code. Task: completed. Experience: broken. Most current benchmarks only count the first part.
EVA evaluates along two independent axes simultaneously:
- EVA-A (Accuracy): Did the agent complete the task deterministically? Did it hallucinate any information? Did it correctly reproduce spoken details like confirmation codes and dollar amounts at the audio level?
- EVA-X (Experience): Was the response appropriately concise for spoken audio — which unlike text, cannot be skimmed? Did the agent avoid repetition? Did it manage turn-taking correctly, neither interrupting the user nor leaving dead silence?
The Speech Fidelity metric inside EVA-A is described as "the first metric ever to evaluate spoken output at the audio level." It listens to whether the agent actually said "AB7-4-2" correctly — not just what appeared in the transcript. A single misheard character in a confirmation code cascades to a full authentication failure. In 50 airline customer service scenarios (covering emergency rebooking, voluntary itinerary changes, cancellations, standby, and compensation vouchers), misheard structured data was identified as the dominant failure mode across all 20 systems tested.
The framework covers both cascade architectures (where the system converts speech to text, processes it with a language model, then converts back to speech — the standard approach) and audio-native architectures (where the model processes audio directly, skipping the text conversion step entirely). Both architecture types failed at multi-step workflows that required preserving ancillary details like seat assignments or baggage allowances. No tested system handled these reliably — the gap between "succeeds at least once" and "succeeds every time" was significant across the board.
EVA is built on Pipecat (an open-source Python framework for voice agents), uses pass@k testing (running each scenario 3 times to measure consistency, not just peak performance), and has published the full dataset — 50 scenarios, 15 tools — on Hugging Face. If you are deploying a voice AI agent for any customer-facing workflow, EVA is now the evaluation standard to benchmark against before launch.
IBM's Three AI Automation Safety Tools for Production
IBM's Granite team completed the week with three specialized "library" models — small, focused models trained to do one thing extremely well — alongside Mellea 0.4.0, a framework for wiring these into production AI pipelines using constrained decoding (a technique that mathematically limits what the AI can output, guaranteeing format compliance rather than just prompting the model to behave correctly).
The three libraries each address a distinct production concern:
- granitelib-rag-r1.0 (14.4 million parameters, 19,400+ Hugging Face downloads) — orchestrates retrieval-augmented generation (RAG) pipelines: deciding what to search for before a query, filtering results after retrieval, and checking the generated answer for accuracy afterward
- granitelib-core-r1.0 — validates AI outputs against requirements in a continuous instruct-validate-repair loop, automatically correcting structured outputs that fail format checks
- granitelib-guardian-r1.0 — monitors responses in real time for safety violations, factual errors, and policy non-compliance
The 19,400+ downloads for the RAG library since launch signal rapid enterprise adoption. These tools are positioned as lightweight alternatives to adding a full large language model layer for pipeline management — at 14.4 million parameters, granitelib-rag is orders of magnitude smaller than a general-purpose LLM, translating to meaningfully lower inference costs at production scale.
One Week, Three Signals That Enterprise AI Has Changed
Three companies, three open-source releases, one week. The common thread is not just new tooling — it is accountability. NVIDIA proved that custom AI training is now both measurable and accessible at a fraction of the historical cost. ServiceNow proved that voice agents require a fundamentally different kind of evaluation than text-based AI. IBM is providing the guardrails that make AI outputs trustworthy enough for regulated production workflows.
The era of deploying general chatbots and hoping for the best is ending. What is replacing it is a more rigorous generation of domain-specific, benchmarked, production-hardened tools — and Hugging Face is the open-source infrastructure layer they are all being built on.
If you are building AI-powered document search, the NVIDIA fine-tuning guide on Hugging Face is the most complete, cost-transparent recipe published yet — run it this week on your own data. If you are shipping a voice AI agent, EVA is the benchmark to test against before you go live. Both are free. Both are open-source. Neither requires anything beyond a cloud GPU rental to try today.
Related Content — Get Started | Guides | More News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments