Salesforce VoiceAgentRAG: 316x Faster Voice AI Response
Salesforce's VoiceAgentRAG slashes voice AI response time from 110ms to 0.35ms — a 316x speedup. 75% cache hit rate. Compatible with Claude, GPT-4o, and Gemini.
Salesforce's VoiceAgentRAG system delivers a 316x speedup in voice AI response time — cutting retrieval latency from 110 milliseconds down to 0.35 milliseconds. This AI automation breakthrough solves one of the hardest problems in real-time conversational AI: making voice assistants feel genuinely instantaneous.
The reason this matters: humans notice a pause of more than 200ms. That's the entire time budget a voice agent has before the conversation starts to feel awkward and robotic. Standard database lookups alone can eat 50–300ms — consuming the whole budget before the AI even starts speaking.
The 200ms Wall That Breaks Every Voice AI Agent
Most AI systems today are built for text — where users can wait 2–10 seconds for a response without noticing much. Voice is completely different. A hesitation that's barely noticeable in a chat window sounds like a dropped call on a phone line.
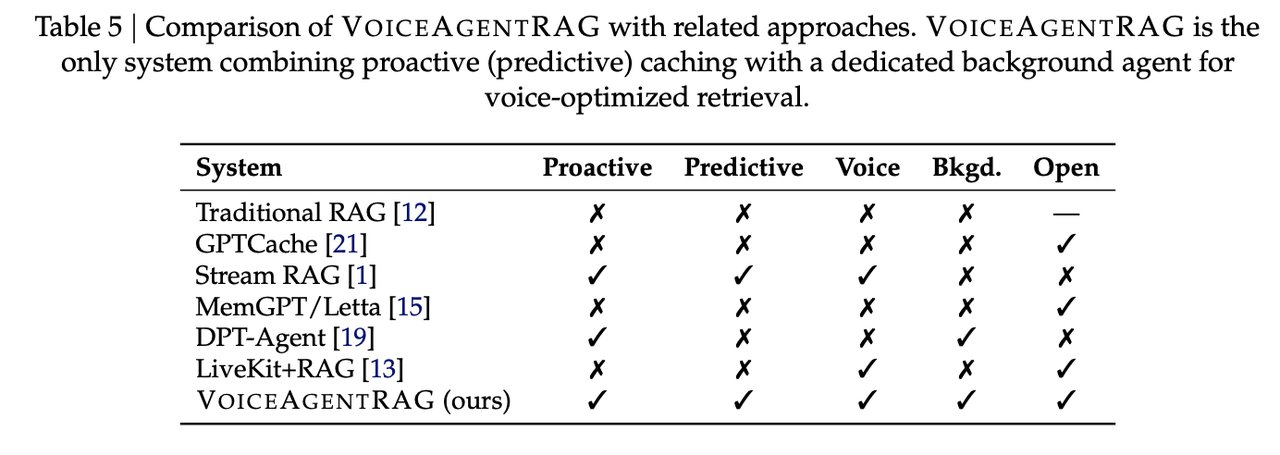
The standard approach is RAG (Retrieval-Augmented Generation — a technique where the AI searches a database of facts before answering). The problem: every RAG lookup requires a round-trip to a vector database (a special database that stores knowledge as mathematical coordinates, letting AI find semantically related information). That single network delay adds 50–300ms to every conversational turn — more than the entire allowed budget.
That bottleneck is exactly what VoiceAgentRAG was designed to eliminate. If you're new to RAG pipelines, the AI automation guides at aiforautomation.io/learn cover the fundamentals from the ground up.
Two Agents, One Conversation: The Dual-Agent Design
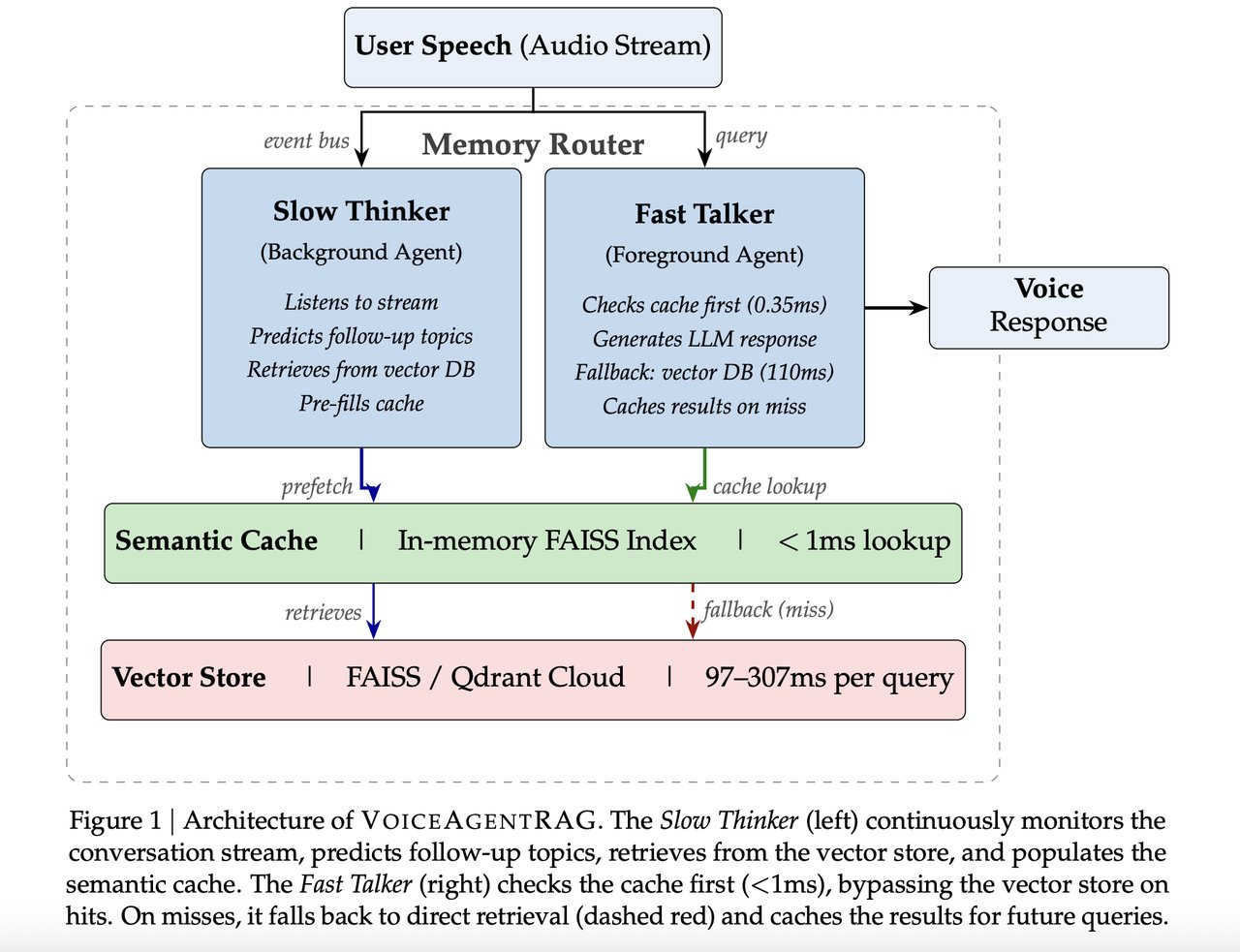
The core innovation is splitting one AI agent into two roles that run simultaneously:
- Fast Talker (foreground): Handles the current question by checking a local in-memory cache (a temporary store of recently retrieved answers sitting on your own machine). Cache lookup takes just 0.35ms — nearly instantaneous.
- Slow Thinker (background): Predicts 3–5 questions the user is likely to ask next, based on a sliding window of the last 6 conversation turns. It pre-fetches those answers in the background while the Fast Talker is still speaking.
By the time the user asks their next question, the answer is already sitting in local memory — no database round-trip required. It's the same principle as a skilled assistant who starts preparing the next answer before you've finished asking the current one.
The Numbers: What a 316x Voice AI Speedup Looks Like
Here's what the benchmark results show:
- Cache hit response time: 0.35ms vs. 110ms for a standard remote database query
- Overall cache hit rate: 75% across all conversation turns
- Warm conversation hit rate: 79% (after a few turns of built-up context)
- Best case — topically coherent conversations (e.g., feature comparisons): 95% hit rate
- Worst case — rapid topic-switching (e.g., customer upgrade flows): 45% hit rate
- Total time saved over a 200-turn conversation: 16.5 seconds
The 316x figure applies specifically to cache hits, which account for 75% of all requests. The remaining 25% still require the standard 110ms remote lookup. The system uses a similarity threshold (τ = 0.40 — a confidence score from 0 to 1 that controls how close a match must be before the cache counts as a hit) to decide when a stored answer is close enough to reuse.
A duplicate detection threshold of 0.95 cosine similarity (a mathematical measure of how similar two pieces of text are, from 0 to 1) prevents the cache from filling with near-identical entries. All cached answers expire after 300 seconds via TTL (Time-To-Live — the lifespan of stored data) to prevent stale information from leaking into responses.
Compatibility: AI Models and Tools Supported
VoiceAgentRAG is open-source and supports a wide range of tools developers are already using:
- AI model providers: OpenAI (GPT-4o-mini tested), Anthropic Claude, Google Gemini and Vertex AI, Ollama (for running models locally without cloud costs)
- Vector stores: FAISS (Facebook AI Similarity Search — a fast local index that runs on your own hardware) and Qdrant Cloud (a hosted option)
- Speech tools: Whisper for speech-to-text (converting spoken words into text the AI can process), Edge TTS, and OpenAI TTS endpoints
- Embedding model tested: OpenAI text-embedding-3-small (a model that converts text into 1,536-dimensional mathematical vectors that AI can compare for similarity)
# VoiceAgentRAG — key configuration at a glance
# Fast Talker: in-memory FAISS cache, 0.35ms lookup
# Slow Thinker: background prefetch of 3–5 predicted topics
# Sliding window: last 6 conversation turns used for prediction
#
# Supported LLMs: OpenAI | Anthropic Claude | Gemini | Ollama
# Vector stores: FAISS (local) | Qdrant Cloud (remote)
# Speech: Whisper | Edge TTS | OpenAI TTS
#
# Cache settings:
# Similarity threshold (τ): 0.40
# Duplicate detection: 0.95 cosine similarity
# TTL (expiry): 300 seconds
# Embedding dimensions: 1,536Who Benefits from VoiceAgentRAG — and Where to Expect Friction
If you're building a voice FAQ bot, customer support agent, or product demo assistant with a consistent set of topics, expect cache hit rates near the 79–95% range. The Slow Thinker's predictions land accurately when conversation follows a logical path — the system thrives on coherent, topic-focused flows.
If your use case involves users jumping between unrelated topics rapidly — a general-purpose assistant or a complex troubleshooting flow — plan for the 45–55% range. In those scenarios, roughly half of requests still hit the standard 110ms path. The system degrades gracefully, but the headline speedup becomes more modest.
The full technical blueprint is published on arXiv (paper 2603.02206) with complete implementation details. If you want to build on these ideas with your own voice setup, the step-by-step guides at aiforautomation.io/learn cover RAG pipeline fundamentals and voice agent setup — no prior research experience needed to get started.
Related Content — Get Started | Guides | More News
Stay updated on AI news
Simple explanations of the latest AI developments