Anthropic just fixed multi-hour AI coding with 3 agents
Anthropic splits AI coding into 3 agents: planning, building, and checking. Keeps multi-hour sessions coherent. LiteLLM attack hits 40,000+ downloads.
Most AI coding assistants start strong. Give them a small task — fix a bug, write a function — and they deliver. But ask them to build something complex over three hours of back-and-forth, and something strange happens: they forget their own decisions, repeat work, contradict themselves, and gradually drift off course.
Anthropic identified this as a structural problem, not a model quality problem. Their answer: stop asking one AI to do everything, and instead coordinate three specialized agents in sequence. Meanwhile, a supply chain attack (a cyberattack that injects malicious code into trusted software packages) just hit one of AI engineering's most-downloaded libraries — exposing exactly how vulnerable this maturing infrastructure still is.
Why Single-Agent AI Coding Falls Apart Over Time
When you give an AI coding assistant an open-ended task — "build me a full-stack authentication system" — the model has to simultaneously hold the architecture in mind, write code, debug errors, and review its own output. Over a long session, these competing demands degrade performance. Context windows (the amount of text an AI can "remember" and work with at once — like short-term memory for a model) fill up. Decisions made in hour one get forgotten by hour three. The result: incoherence at scale.
Anthropic's solution, called a three-agent harness (a coordinated system where multiple AI agents each own one specific job in a workflow), divides this cognitive load into three explicit, isolated roles:
- Planning agent — Sets the strategy, defines the architecture, and writes a full specification before any code is written
- Generation agent — Focuses exclusively on writing code, operating strictly within the boundaries the planner established
- Evaluation agent — Reviews the generated code for quality, correctness, and consistency with the original plan — acting as a built-in QA layer

The architecture specifically targets multi-hour autonomous coding sessions — the kind where a developer sets up a task before lunch and expects meaningful, coherent output by end of day. In traditional single-agent setups, those sessions tend to degrade as each agent's context window fills with the noise of its own work. Separating the roles keeps each agent's working memory focused and constrained to what it actually needs.
The Director Model: Treating AI Like a Team
At QCon SF 2025, Adrian Cockcroft — former Netflix cloud architect and now a prominent voice in AI infrastructure design — described this pattern as "director-level" orchestration. The framing: position the planning agent like a project lead managing a team of specialists, rather than hiring one generalist to design, build, and QA a system simultaneously. Tools like Cursor and Claude Flow already support variations of this workflow in production environments.
The broader shift is significant. As AI coding moves from "chatbot-style prompting" to "sustained autonomous execution spanning hours," the same management principles that make large engineering teams productive start to apply. Unstructured, monolithic approaches fail at scale — whether the workers are humans or AI agents.
PostgreSQL as a Folder: The Idea Behind TigerFS
A separate but related development targets a different pain point: how AI agents interact with databases. Historically, an agent that needs data from a PostgreSQL database (one of the world's most widely-used open-source relational databases, trusted by companies like Apple, Reddit, and Instagram to store structured data) must go through either a REST API (a web-based interface for requesting specific data) or an SDK (a software development kit — pre-written code that handles database connections and query formatting). Both require configuration and specialized knowledge.

TigerFS, an experimental open-source project, takes a radically different approach: it mounts your PostgreSQL database as a standard directory on your computer. Tables become folders. Rows become files. And suddenly, you can interact with your database using commands every developer already knows:
# Browse database tables like directories
ls /db/users/
# Read a specific row like a plain text file
cat /db/users/user_42
# Search across all records with grep
grep "premium" /db/subscriptions/*
# Find records matching time criteria
find /db/orders/ -name "*.json" -newer yesterdayThe specific advantage for AI agents: models tend to perform better with filesystem abstractions (navigating folders and files) than with API calls that require constructing structured queries. An agent using TigerFS can navigate a PostgreSQL database the same way it navigates a code repository — no new interface to configure mid-session, no credentials to manage per-query.
Critical caveat: TigerFS is explicitly labeled "experimental." Production deployment is not advisable, and no public performance benchmarks exist yet. It's a proof-of-concept for where AI-friendly data infrastructure is heading — a direction worth watching, but not a tool to ship with today.
GitHub's Accessibility Inspector That Never Clocks Out
Accessibility compliance — ensuring software works for people with visual, motor, or cognitive disabilities, as defined by WCAG standards (the Web Content Accessibility Guidelines, a formal specification maintained by the W3C international web standards body) — has historically been treated as a backlog item. Engineering teams accumulate reports from user feedback forms, automated scanners, and pull request comments with no unified system to triage them.
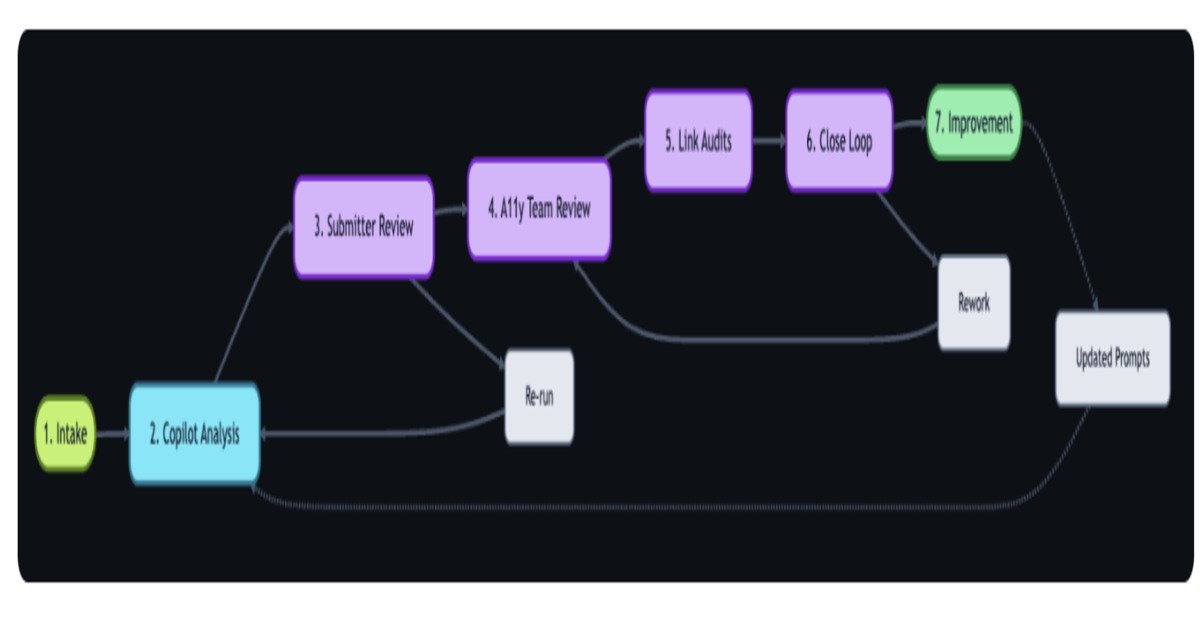
GitHub built a continuous AI-powered workflow that centralizes this process using 3 integrated tools working in sequence:
- GitHub Actions — The automation backbone (think of it as a robotic assembly line that activates whenever a new accessibility report arrives from any source)
- GitHub Copilot — Analyzes each report against WCAG guidelines and categorizes the type and severity of the issue
- GitHub Models APIs — Powers the deeper routing logic, scoring each report and directing it to the right team
The workflow automatically classifies incoming reports, tags them by WCAG violation type and severity, and routes them to the right team — consolidating reports that previously arrived through 5 or more disconnected channels into a single managed queue.
Critically, GitHub deliberately kept a human validation step in the loop. The AI categorizes and prioritizes; a person confirms before anything is acted upon. This "AI triage, human decision" model is becoming the standard architecture for mature deployments — eliminating tedious sorting work without removing humans from consequential choices.
40,000 Downloads of Malware Hidden in a Trusted AI Library
While the engineering community builds better AI infrastructure, attackers are targeting that same infrastructure. A recent supply chain attack against LiteLLM — a widely-used open-source library that connects AI applications to multiple language models including GPT-4, Claude, and Gemini — compromised more than 40,000 downloads of a malicious package version. LiteLLM's baseline traffic runs approximately 3 million downloads per day.
The attack vector was the package registry itself — the online library where developers fetch code dependencies (analogous to a mobile app store, but for code that runs inside other programs). Developers who downloaded the malicious version had every reason to trust it; it came from a legitimate-appearing update to a package they already relied on.
The scale of exposure isn't just the 40,000 downloads. It's what those downloads power. LiteLLM sits at the core of many production AI applications, and those applications often carry elevated permissions — they can read files, access databases, execute commands, and make external API calls. A compromised dependency in this position has a far larger potential blast radius than a compromised dependency in a typical web application.
Research from Teleport cited alongside the incident found that AI systems with over-privileged access experience 4.5x more security incidents than those with properly scoped permissions. The LiteLLM attack makes the gap concrete: identity and access management (the discipline of controlling exactly which systems can do what, and verifying they are who they claim to be) has not kept pace with the rapid deployment of AI infrastructure.
If your team uses LiteLLM in any production workflow: audit your installed version history and pin to a verified, known-good release immediately.
Four Stories, One Pattern: AI Infrastructure Entering Its Production Era
The Anthropic three-agent harness, TigerFS, GitHub's accessibility pipeline, and the LiteLLM attack share an underlying thread — AI tooling is transitioning from experimental to production-grade, and that transition comes with both new capabilities and new attack surfaces.
- Structure is replacing improvisation. Anthropic's harness applies formal separation of concerns — the same engineering discipline that makes large codebases maintainable — to AI-driven development workflows.
- AI-native interfaces are being layered onto existing infrastructure. TigerFS doesn't rebuild PostgreSQL — it adds a translation layer that makes existing data feel native to how AI agents already operate.
- Compliance is being automated into pipelines. GitHub's workflow shows that AI can eliminate the tedious triage work without automating away human judgment at the critical decision points.
- Critical infrastructure attracts adversarial attention. With 3 million daily downloads, LiteLLM is now as critical as any database driver or authentication library — and faces the same threat model.
ProxySQL — a widely-used database proxy favored by high-scale engineering teams — acknowledged this maturation directly by introducing a dedicated AI/MCP exploration track as the third tier of its new 3-tier release strategy. AI compatibility has moved from feature request to release category. That's a quiet signal that the production era is here.
Related Content — Get Started | Guides | More News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments