Gemma 2B Beats GPT-3.5 Turbo: Free Local AI for Any Laptop
Gemma 2B scored 1,126 vs GPT-3.5 Turbo's 1,116 in real human tests. Free to download — runs offline on any 8GB laptop with zero API costs.
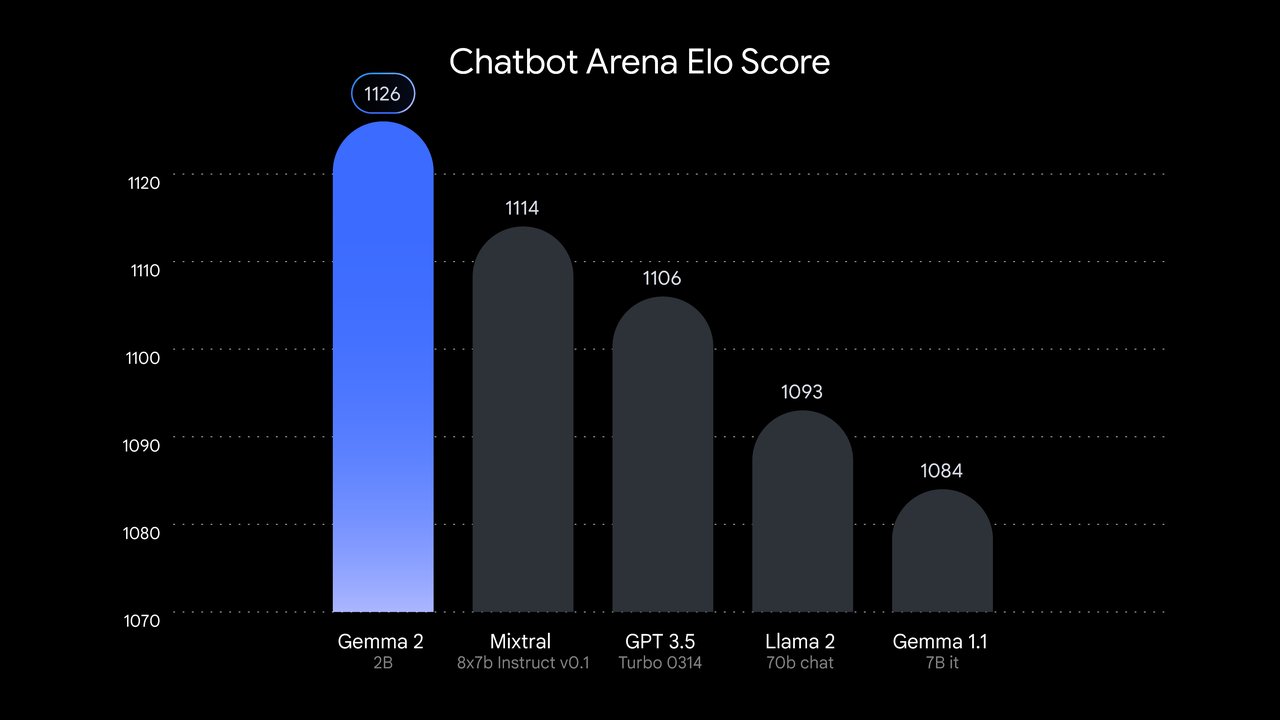
On July 31, 2024, Google released Gemma 2 2B — a free local AI model with 2.6 billion parameters — and it immediately did something that made developers stop and recheck the numbers. On the LMSYS Chatbot Arena (a benchmark where real humans vote for the better AI response without knowing which model they're testing), Gemma 2 2B outscored every GPT-3.5 variant OpenAI has released. The score: 1,126 for Gemma versus 1,116 for GPT-3.5 Turbo. That's a model 67 times smaller — completely free to download and run on your own hardware. If you've been paying per token for GPT-3.5 Turbo, the math on that decision just changed.
How a 2.6B AI Model Beat GPT-3.5 Turbo at Human Conversation
Parameter count (the number of numeric weights an AI model uses to store knowledge — more parameters roughly equal more raw capacity) has been the dominant proxy for AI quality for years. GPT-3.5 Turbo is estimated at approximately 175 billion parameters. Gemma 2 2B operates with just 2.6 billion — roughly 1.5% of GPT-3.5's scale. On raw size alone, there should be no contest. And yet, when real humans compare responses side-by-side without knowing which model produced them, they consistently prefer Gemma's answers.
The mechanism behind this result is a training technique called knowledge distillation (a method where a small model learns not only from raw text data, but by mimicking a much larger "teacher" model — absorbing its reasoning style without inheriting its computational cost). Google used its larger Gemma variants to supervise the 2B training process, compressing the conversational quality of a far bigger system into a fraction of the parameter budget.
Gemma 2 2B was also trained on 2 trillion tokens (a token is roughly three-quarters of a word — so 2 trillion tokens equals approximately 1.5 trillion words of text). That is a massive dataset for a model this size, which explains why its factual grounding and language comprehension scores sit well above what the parameter count alone would predict.
Gemma 2B vs GPT-3.5 Turbo: Benchmark Scores Side by Side
- LMSYS Chatbot Arena Elo (human preference vote — millions of real side-by-side comparisons): Gemma 2B: 1,126 vs. GPT-3.5 Turbo: 1,116 — Gemma wins
- MMLU — Massive Multitask Language Understanding (a 57-subject test covering law, science, history, and math): 51.3%
- HellaSwag (common-sense sentence completion): 73.0%
- ARC-e — AI2 Reasoning Challenge (elementary science questions): 80.1%
- GSM8K (grade-school math word problems): 23.9%
One honest caveat: Gemma 2B scores 23.9% on math — well below GPT-3.5 Turbo's ~57% on the same benchmark. For applications requiring precise numerical calculations or multi-step arithmetic, the larger cloud model holds a clear advantage. But for writing, summarizing, explaining, and general conversation — which covers the overwhelming majority of real-world AI use — Gemma 2B is a legitimate, zero-cost alternative.
The True Cost: $0.50 Per Million Tokens vs. $0 for Local AI
GPT-3.5 Turbo is accessed via OpenAI's API (an interface that lets software send text to OpenAI's servers and receive responses, with cost calculated per token processed). As of its 2024 pricing schedule: $0.50 per million input tokens and $1.50 per million output tokens. A modest chatbot handling 1,000 conversations per day at 500 tokens each generates 500,000 tokens daily — roughly $250 per month, every month, with that number subject to change whenever OpenAI adjusts its pricing.
Gemma 2 2B costs nothing after a one-time download. The model file is approximately 4.67 GB — about the size of two HD movies. Once it lives on your machine, every query you run costs exactly $0. No rate limits. No API key. No third-party server ever processes your content. Google confirmed that Gemma 2 2B also runs on free-tier T4 GPUs (a type of graphics card available inside Google's free Colab cloud notebooks — a browser-based coding environment anyone can use without a paid subscription), making it accessible even without local GPU hardware.

Running Gemma 2B Local AI on Your Own Machine
The minimum hardware bar is lower than most expect. A laptop with 8GB of RAM handles quantized versions of Gemma 2 2B (quantized meaning the model's numerical precision is reduced to shrink its memory footprint — similar to how saving a photo as a JPEG reduces file size while preserving most image quality). A 16GB machine runs the full-precision model comfortably. Apple Mac users get native support via the MPS backend (Metal Performance Shaders — Apple's GPU acceleration framework that enables near-GPU-speed AI inference on Mac hardware, no NVIDIA card required).
The fastest path from zero to a running local model is a single install command:
pip install local-gemmaThen run a prompt directly from the terminal:
local-gemma --model "google/gemma-2-2b-it" --prompt "Summarize this email in three bullet points: ..."The -it suffix stands for instruction-tuned (a version specifically fine-tuned to follow directions and hold conversations — as opposed to the base model, which simply continues text patterns without engaging with your request). For Python developers who want more control over generation:
from transformers import pipeline
pipe = pipeline(
"text-generation",
model="google/gemma-2-2b-it",
device="mps", # "cuda" for NVIDIA GPUs, "cpu" as fallback
)
result = pipe("Draft a professional reply declining a meeting request", max_new_tokens=300)
print(result[0]["generated_text"])The Transformers library (an open-source Python toolkit maintained by Hugging Face — a company that hosts AI model downloads and provides developer tools — that handles model loading, memory management, and device compatibility automatically) downloads Gemma 2 2B on first run and caches it locally. Every subsequent query runs entirely offline.
For device-specific setup instructions and configuration options, our AI automation setup guide covers every step from installation to first query.
What Gemma 2B Means for AI Automation and Local AI Development
This benchmark result reflects a pattern accelerating across the AI landscape: the performance gap between large proprietary cloud models and compact open alternatives is closing fast. Models requiring multi-billion-dollar infrastructure to train just two years ago are now downloadable by anyone with a consumer laptop. Knowledge distillation, better training data curation, and architectural improvements — Gemma 2 uses interleaved local-global attention layers (a design that alternates between focusing on nearby words and attending to the full document context, improving coherence without increasing parameter count) — are compressing the gap at every release cycle.
For privacy-sensitive workflows — legal document review, medical note drafting, personal financial planning, confidential business writing — this shift carries real weight. Text sent to GPT-3.5 Turbo via API passes through OpenAI's infrastructure. Text processed by a local Gemma 2B instance never leaves your device. No query is ever logged, stored, or potentially used to train future models outside your control.
You can download Gemma 2 2B today from Hugging Face. The full model family is documented at Google AI for Developers. For a step-by-step guide to running local AI tools without prior coding experience, the AI for Automation learning guides walk you through setup on any device.
Related Content — Get Started | Guides | More News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments