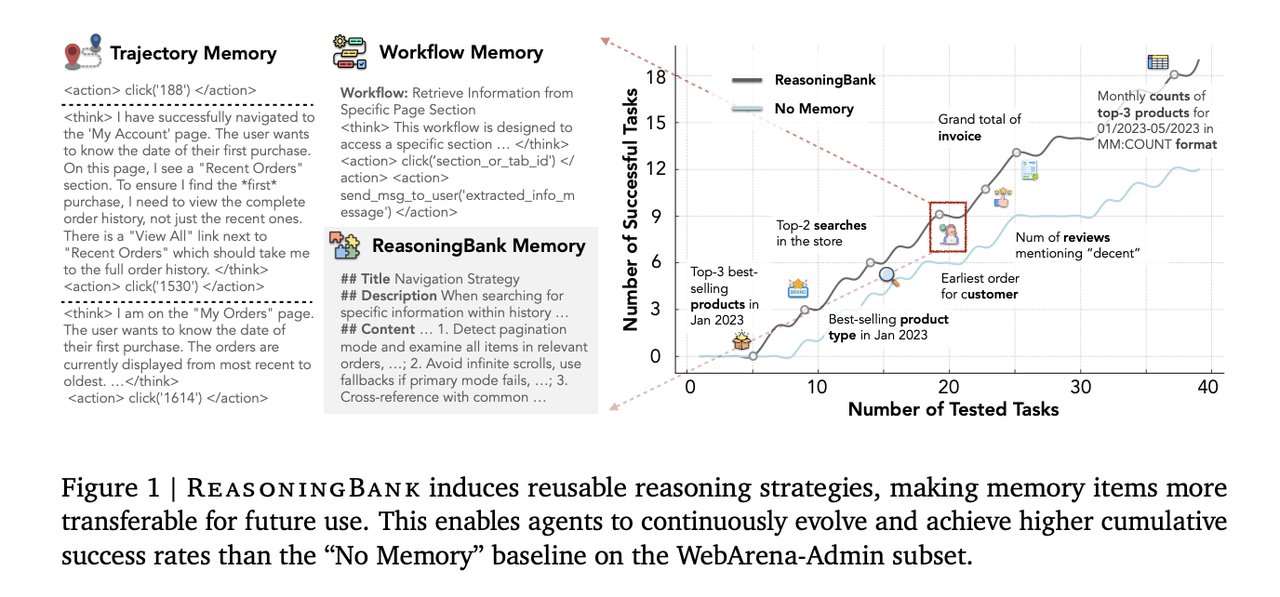
AI Agents Learn From Failure: ReasoningBank & MiMo-V2.5
Google's ReasoningBank gives AI agents failure memory — boosting task success 8.3%. Xiaomi MiMo-V2.5-Pro built a full compiler in 4.3 hours, scoring 233/233.
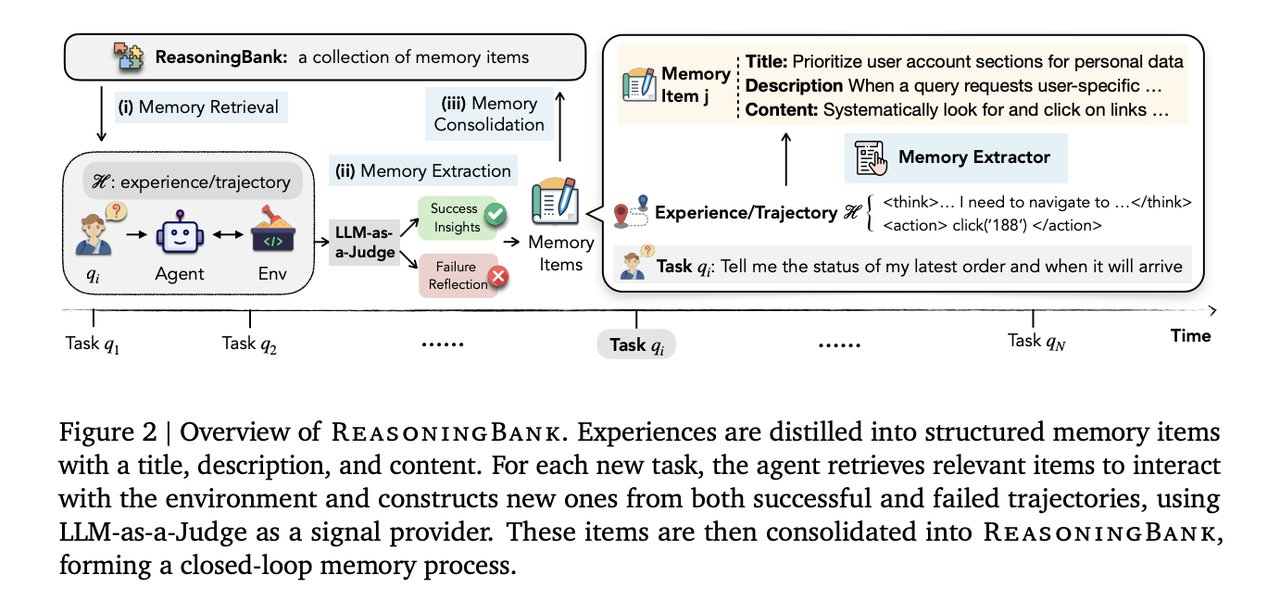
Every time an AI agent finishes a task in an AI automation workflow — whether it succeeds or fails — it discards the experience and starts fresh. That is the hidden design flaw in every major agent memory system. Google Cloud AI researchers, working with UIUC and Yale, published ReasoningBank: a new memory framework that finally treats failures as learning opportunities, not garbage. The result: 8.3 percentage points better task success on real-world web benchmarks.
The same week, Xiaomi released MiMo-V2.5-Pro — an open-source agentic model (an AI built to complete multi-step tasks autonomously, rather than just answering questions) that completed a full Rust compiler in 4.3 hours across 672 tool calls, scoring a perfect 233/233 on a hidden test suite. That is a project university computer science students typically spend several weeks completing.
The Hidden Flaw: AI Agents That Never Learn From Failure
Today's most-used agent memory systems — Synapse and AWM (Agent Workflow Memory, a framework where agents accumulate reusable task strategies over time) — share one fundamental design flaw: they only extract lessons from successful tasks. Every failed attempt is classified and thrown away. All the counterfactual information about what went wrong, what not to try, and why an approach failed disappears.
ReasoningBank fixes this with a three-part memory structure applied to every outcome, success or failure:
- Title: A short strategy label (e.g., "Pagination Handling")
- Description: One-sentence explanation of the approach
- Content: 1–3 sentences of detailed reasoning about when and how to apply the lesson
After each task, a process called "LLM-as-a-Judge" (using an AI model to classify whether a task succeeded or failed — like an automated quality reviewer) extracts the key lesson and stores it in memory. The judge only needs to be correct about 70% of the time to keep the system robust — well within reach of current models.
More Memory Is Not Better — The k=1 Finding for Agent Memory
The most counterintuitive result in the research: retrieving more memories consistently hurts performance.
- k=1 (one memory item retrieved): 49.7% task success on WebArena (a benchmark for automated web navigation — think filling forms, finding information across multiple pages)
- k=4 (four memory items retrieved): 44.4% success rate — a 5.3-point drop from using a single item
The explanation: an agent given one highly relevant lesson uses it cleanly. An agent given four must decide which applies, and context overload degrades decision quality. For anyone building agent pipelines (sequences of automated AI steps that complete complex tasks), the practical implication is clear: surface fewer, higher-quality context items rather than flooding the model with options.
Full benchmark improvements across three test environments:
- WebArena: 40.5% → 48.8% (+8.3 percentage points)
- SWE-Bench-Verified with Gemini-2.5-Pro: 54.0% → 57.4%
- SWE-Bench-Verified with Gemini-2.5-Flash: 34.2% → 38.8%
- Average steps saved per task: 1.4 fewer vs. no-memory, 1.6 fewer vs. other memory systems
- Shopping task efficiency: 26.9% relative reduction, 2.1 steps saved per task
With MaTTS (Memory-Aware Test-Time Scaling — a technique that runs multiple task trajectories as parallel learning signals, then consolidates lessons across all of them), WebArena performance climbs to 56.3% vs. a 46.7% no-memory baseline, with tasks completed in 7.1 steps vs. 8.8 on average.
How AI Agent Memories Evolve Over Time
Early agent memories look like simple checklists. A web navigation agent might start with: "Actively look for and click on Next Page, Page X, or Load More links."
After accumulating more task experience, that same memory evolves into something compositional: "Regularly cross-reference the current view with task requirements; if data does not align with expectations, reassess available options before proceeding."
That is the jump from a static checklist item to a genuine heuristic (a problem-solving rule developed through accumulated experience). ReasoningBank does not freeze memories at first capture — it consolidates and replaces simpler strategies with richer ones as more tasks accumulate, automatically.
// Example ReasoningBank memory item (simplified structure)
{
"title": "Pagination Handling",
"description": "Navigate multi-page results by identifying pagination controls before concluding.",
"content": "Look for Next Page, numbered pages, or Load More before declaring no results exist. Scroll to bottom — pagination controls may load lazily on the page.",
"source": "failure",
"confidence": 0.82
}Xiaomi MiMo-V2.5-Pro: Open-Source AI Agent Matching Frontier Models
MiMo-V2.5-Pro is Xiaomi's open-source agentic model — a publicly available AI designed specifically for autonomous multi-step task completion — positioned as a cost-competitive alternative to frontier closed-source models (proprietary AI systems from Anthropic or OpenAI that charge per-token pricing). Its benchmark scores back that positioning:
- SWE-bench Pro: 57.2
- Claw-Eval: 63.8
- τ³-Bench (a long-horizon task reasoning benchmark testing sustained coherence across complex, multi-step problems): 72.9
The demo that makes the capability concrete: starting from a completely blank workspace, MiMo-V2.5-Pro autonomously built a complete SysY compiler in Rust — including a lexer (the component that breaks source code into meaningful tokens), a parser (the component that builds grammatical structure from those tokens), an AST or Abstract Syntax Tree (a structured map of the program's logic), code generation, backend passes, and optimization routines.
Final result: 4.3 hours. 672 tool calls. 233/233 on the hidden test suite. The first compile attempt scored 137/233 (59%) before any test-suite feedback — indicating correct architectural planning from the start, not iterative trial-and-error guessing.
The property Xiaomi calls "harness awareness" (the model's ability to actively reorganize its working environment as a task progresses, rather than executing a fixed plan in sequence) allowed MiMo to sustain coherent behavior across 1,000+ tool calls — a threshold where most current agent models lose the thread entirely.
What Changes for Teams Using AI Agents Today
If your team deploys AI agents for any repetitive workflow — browser automation, code generation, data extraction, or customer support ticket routing — two facts are now true that were not six months ago:
- Failure-learning memory is documented and achievable. ReasoningBank's full research paper is available at arxiv.org. The code framework is referenced in the paper with a public release in progress. Comparing your current agent memory architecture against this standard is worth doing now — before your next deployment cycle.
- Open-source agents now score alongside expensive frontier APIs. MiMo-V2.5-Pro is available via Xiaomi's API at significantly lower token cost. Full access details are in the release announcement. If you are paying frontier-model prices for agentic tasks, benchmark this against your actual workloads before your next contract renewal.
The practical next step: add does it learn from failures? to your agent evaluation criteria. Read how agent memory fits into real automation pipelines — then run MiMo against your current provider before you commit to another year of per-token pricing. An agent that improves from experience is now a requirement you can ask for, not a roadmap promise you have to wait for.
Related Content — Get Started | Guides | More News
Stay updated on AI news
Simple explanations of the latest AI developments