DeepSeek-V4 Beats GPT-5.4 at Coding: 3x Leaner AI
DeepSeek-V4 tops Codeforces at 3206, beating GPT-5.4 and Gemini. Open weights, 49B active of 1.6T params — 3x leaner inference for AI automation teams.
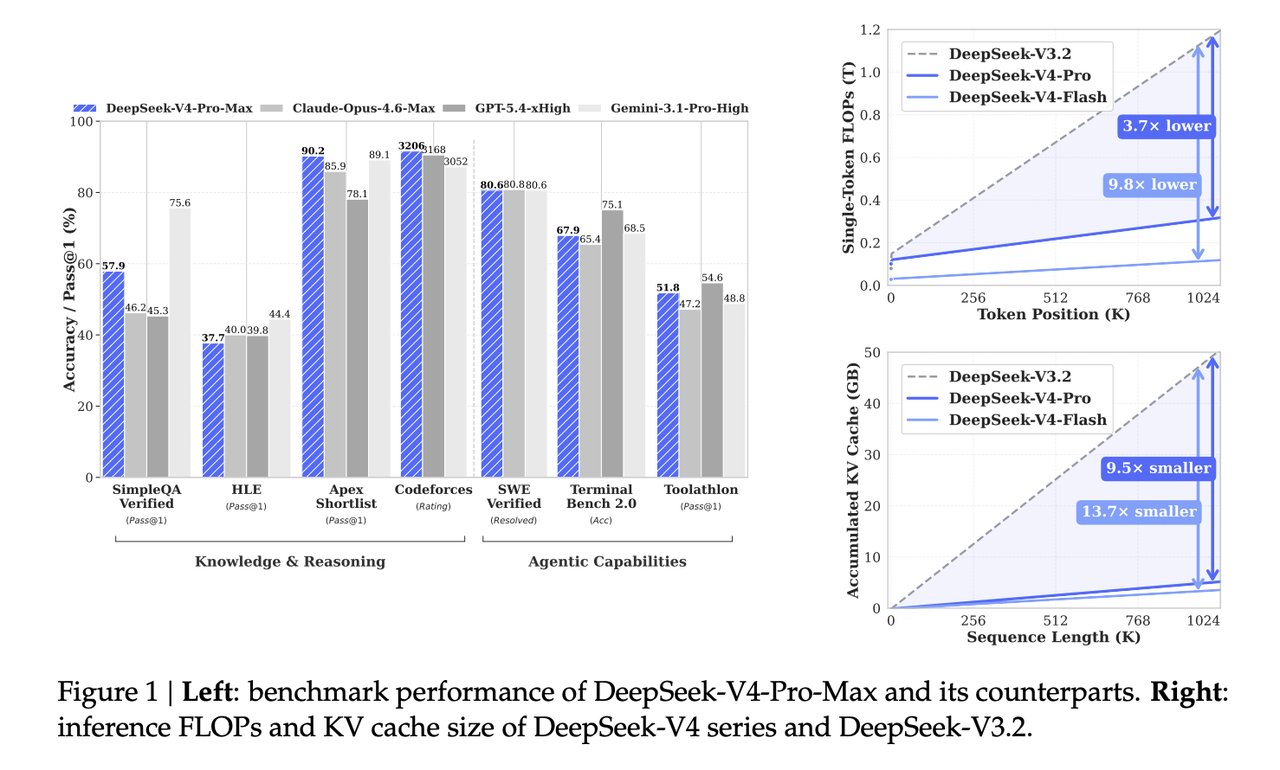
DeepSeek-V4-Pro-Max placed first on Codeforces with a rating of 3206 — 38 points ahead of GPT-5.4-xHigh and 154 points ahead of Gemini-3.1-Pro-High. That result landed without a press release or launch event. What makes it more than a benchmark trophy: DeepSeek-V4 achieves those scores while activating only 49 billion of its 1.6 trillion total parameters per token — roughly 3x fewer active parameters than its predecessor, for lower cost and faster inference on identical hardware — a structural efficiency gain for AI automation and enterprise LLM deployments.
This is not an incremental update. The combination of new benchmark leadership and a 90% reduction in memory requirements for million-token context windows signals a structural shift in what frontier AI efficiency looks like heading into 2027.
AI Coding Leaderboard Shift No One Announced
DeepSeek-V4 ships in two variants. The flagship DeepSeek-V4-Pro carries 1.6 trillion total parameters with 49 billion activated per query (query meaning each prompt or message the model processes). The leaner DeepSeek-V4-Flash holds 284 billion total parameters with just 13 billion activated — yet it outperforms the V3.2 baseline despite using 3x fewer active parameters at runtime.
On Codeforces (the world's largest competitive programming platform, where AI models are ranked by their ability to solve real algorithmic challenges under timed competition conditions), the full picture:
- 3206 — DeepSeek-V4-Pro-Max (1st place)
- 3168 — GPT-5.4-xHigh (2nd, −38 points behind)
- 3052 — Gemini-3.1-Pro-High (3rd, −154 points behind)
On SimpleQA Verified (a factual accuracy benchmark that penalizes both wrong answers and unhelpful hedging — the model must commit to a correct answer to score), DeepSeek-V4-Pro-Max scored 57.9% Pass@1, beating Claude Opus 4.6 Max at 46.2% and GPT-5.4-xHigh at 45.3%. Gemini-3.1-Pro-High leads this category at 75.6%, a gap that remains real and significant.
On SWE-Verified (a benchmark that tests whether AI can resolve genuine GitHub issues — not synthetic exercises, but real reported bugs from open-source projects), DeepSeek-V4-Pro-Max resolved 80.6% of cases, making it a strong candidate for practical software engineering workflows.
The model has one clear limitation: on the OpenAI MRCR 1M benchmark (a long-context memory test that evaluates retrieval and reasoning over one million tokens — roughly 750,000 words, equivalent to about ten full-length novels in a single session), Claude Opus 4.6 Max leads at 92.9 MMR versus DeepSeek-V4's 83.5 MMR. If your primary use case involves reading entire codebases or 500-page legal documents in one pass, Claude still holds the edge on that dimension.
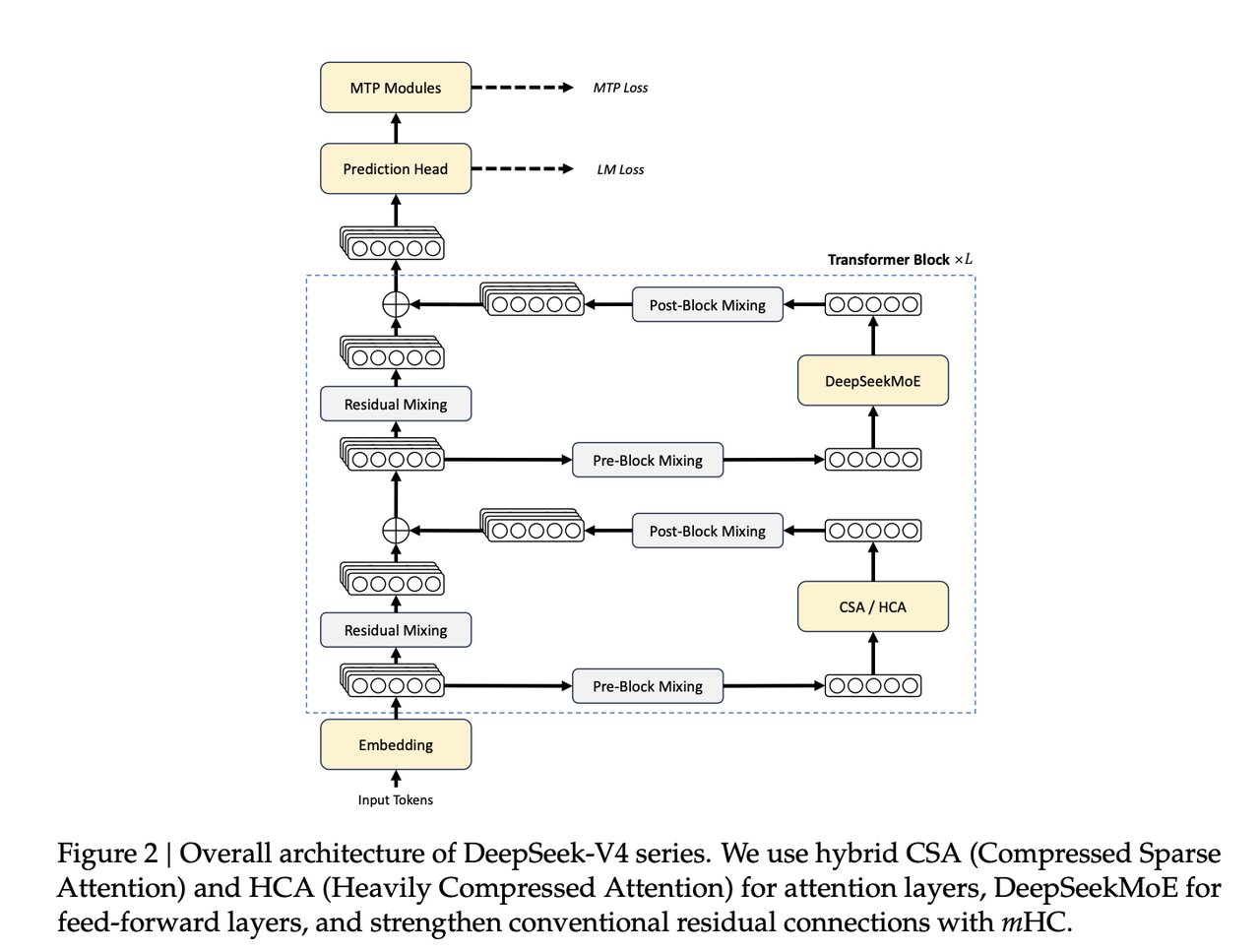
Doing More With 3x Less: DeepSeek-V4 Mixture of Experts Architecture Explained
Most large language models (LLMs — AI systems trained on text that generate responses by predicting the next word or token) activate every one of their parameters for every input. DeepSeek-V4 uses Mixture of Experts (MoE — an architecture where only a small fraction of the model's total capacity is switched on per input, dramatically lowering the compute cost of each inference call). The innovation in V4 is how it extends this approach to extremely long contexts without a memory explosion.
The key is a hybrid attention mechanism combining CSA (Compressed Sparse Attention — which efficiently handles nearby context, the most recent tokens in a conversation or document) with HCA (Heavily Compressed Attention — which handles long-range dependencies at drastically lower memory cost). Together, they shrink the KV cache (the working memory an AI model uses to keep track of everything it has read in a session) to just 10% of what DeepSeek-V3.2 required at one million tokens. That is a 90% reduction in the memory cost of long-context inference.
For teams running inference at scale, that 10% figure translates directly into infrastructure costs. A workload that previously required 10 high-memory GPUs could potentially run on one. Both variants were pre-trained on massive datasets before fine-tuning:
- DeepSeek-V4-Pro: trained on 33 trillion tokens of text
- DeepSeek-V4-Flash: trained on 32 trillion tokens of text
Model weights for both variants are publicly available. Teams can download and run them without a subscription or API key dependency:
# Download DeepSeek-V4 model weights from Hugging Face (requires Git LFS)
git clone https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
git clone https://huggingface.co/deepseek-ai/DeepSeek-V4-FlashFP4 quantization (a compression technique that stores model weights at lower numerical precision, trading a marginal accuracy loss for large memory savings) is applied to the expert weights in both variants, enabling the models to run on hardware that would otherwise be insufficient for trillion-parameter systems. The accuracy trade-off is minimal in practice — the benchmark results above reflect quantized inference.
Google DeepMind's Distributed AI Training Revolution
While DeepSeek headlines the benchmark results, a parallel development from Google DeepMind may matter more for how AI training gets built over the next three years. Training frontier AI models currently requires thousands of chips networked together with ultra-fast interconnects inside a single facility. Running training across multiple data centers has been practically impossible — the data flow between machines in real time demands dedicated fiber links at 100+ Gbps, infrastructure that only hyperscalers like Google, Amazon, and Microsoft maintain at scale.
DeepMind's Decoupled DiLoCo (DiLoCo stands for Distributed Low-Communication training — a method that decouples how frequently model weight updates must be synchronized across locations, slashing the bandwidth requirement by eliminating the need for constant cross-site coordination) changes that equation entirely:
- Conventional distributed training: 198 Gbps of inter-datacenter bandwidth required
- Decoupled DiLoCo: just 0.84 Gbps — a 240x reduction
- Standard commercial internet at 2–5 Gbps is now sufficient for full multi-region training runs
The efficiency metric that captures real-world impact is goodput (the percentage of total training time that actually produces useful model improvements, versus time wasted recovering from hardware failures, reloading checkpoints, or waiting on data transfers). Decoupled DiLoCo achieves 88% goodput. Standard data-parallel training (the conventional approach where all machines synchronize weights after every optimization step) achieves only 27% goodput under realistic hardware failure rates — meaning more than two-thirds of compute time produces no useful training progress.
DeepMind validated the approach at real scale: a 12 billion-parameter Gemma 4 model was trained across four U.S. data center regions simultaneously, using only 2–5 Gbps of WAN bandwidth — commercially available speeds, not custom infrastructure. The accuracy difference from conventional single-datacenter training was just 0.3 percentage points (64.1% vs 64.4% on ML benchmarks), negligible for production use.
The team also ran chaos engineering tests (deliberate stress tests that simulate hardware failures at massive scale to verify the system recovers without losing training progress) across a simulated environment of 1.2 million chips under high failure rates. Self-healing held up throughout — a critical signal for any training run spanning weeks or months on distributed hardware that cannot afford a full restart after a machine incident.
Two AI Automation Decisions Teams Should Make This Week
Both systems are available now, and both affect near-term decisions in ways that are easy to act on.
If you're evaluating model upgrades for coding or general knowledge tasks: DeepSeek-V4-Pro is now the benchmark leader ahead of GPT-5.4 and Claude Opus 4.6 Max in those categories. The exception is long-context retrieval — Claude Opus 4.6 Max holds the lead at 92.9 MMR versus DeepSeek's 83.5. Standard conversations and document analysis favor DeepSeek-V4's efficiency advantage; full-codebase single-session analysis still benefits from Claude's long-context lead. Run both against your specific workload before committing.
If you're planning AI training infrastructure for 2026–2027: The Decoupled DiLoCo result suggests that training large models will no longer require exclusive access to hyperscaler data centers. Organizations with geographically distributed compute and commercial internet can now potentially run production-grade training. That changes competitive dynamics for enterprise AI teams and startups building proprietary models — watch this space closely.
DeepSeek-V4 weights are downloadable today from Hugging Face. Full architecture details are in the DeepSeek-V4 technical whitepaper. DeepMind's training research is covered in their Decoupled DiLoCo blog post. For practical guidance on choosing the right AI model for your specific workflow, the AI model selection guides on this site walk through the benchmarks that matter for non-research teams.
Related Content — Get Started | Guides | More News
Sources
Stay updated on AI news
Simple explanations of the latest AI developments