Someone just ran AI on a 26-year-old PlayStation 2
A developer built a working AI language model on a PlayStation 2 with just 32 MB of RAM — streaming model weights from CD-ROM one layer at a time.
A developer just proved that AI can run on almost anything — including a 26-year-old PlayStation 2 with just 32 MB of RAM and a 294 MHz processor. The project, called PS2-LLM, runs a working language model (the kind of AI behind tools like ChatGPT) directly on original PS2 hardware — no modifications, no tricks.
The catch? The model streams its "brain" from a CD-ROM disc, one piece at a time, because the entire model doesn't fit in memory. It's slow, the outputs are nonsensical, and it's completely impractical. But it works — and that's the point.
How do you fit AI inside a console from the year 2000?
The PlayStation 2 has 32 MB of total RAM — roughly 500 times less than a typical laptop today. Even the smallest useful AI model is bigger than that. So developer Samuel Cortes Rojas came up with an elegant workaround: stream the model weights from CD-ROM during inference.
Here's how it works in plain English:
Normal AI: Load the entire model into memory → process your question → generate an answer.
PS2 AI: Read one tiny slice of the model from the CD-ROM → process that slice → throw it away → read the next slice → repeat hundreds of times → eventually produce one word.
Only the bare essentials stay in RAM: the current conversation context, word embeddings (the AI's vocabulary), and a small cache. Everything else gets read from disc on the fly.
Five models tested — here's what actually ran
The developer tested five different AI models, pushing the PS2 to its limits:
brandon-tiny-10m (10.4 MB) — The default model. Uses a clever trick called "block sharing" where 11 unique layers are reused cyclically to create 22 logical layers. This means the CD-ROM laser only needs to read 11 slices per word generated, keeping speed tolerable.
TinyLlama 110M (30 MB, 4-bit compressed) — A "real" AI model squeezed down to fit. It works, but each word requires reading 12 layers from disc sequentially.
SmolLM2-135M (77 MB, 4-bit compressed) — The largest model tested. At 30 layers, it's roughly 2.5x slower than the smaller models. The verdict: "speed penalty too high for practical PS2 use." Yes, there's a bar for "practical PS2 AI use" now.
The output is gloriously terrible
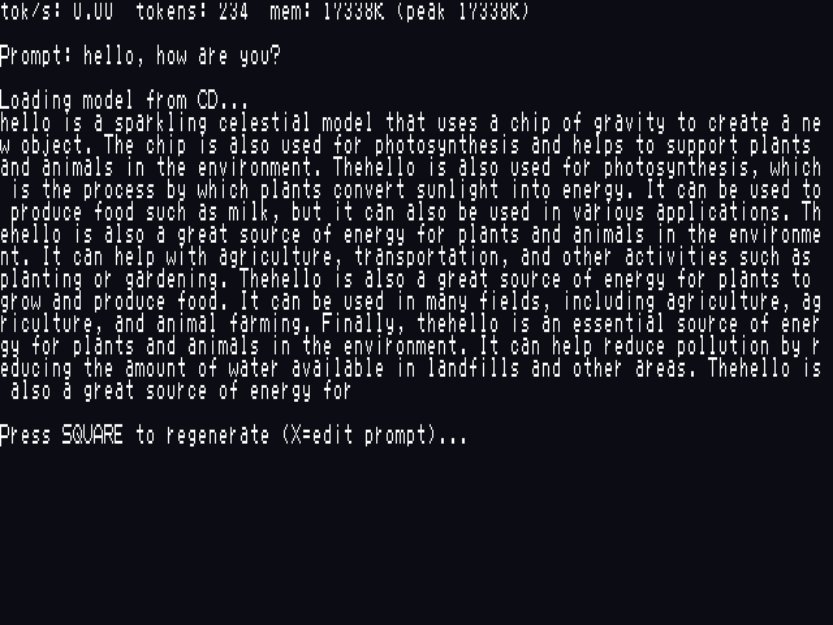
When asked "hello, how are you?" the PS2's AI responded with a stream-of-consciousness monologue about "a sparkling celestial model that uses a chip of gravity to create an object" and how "thehello is a great source of energy for plants and animals."
It's not useful. It's not coherent. But it is a transformer-based language model running inference on a MIPS-III processor from 1999, streaming weights off a spinning disc. The fact that it produces grammatically structured English at all is remarkable.
Why this actually matters
This project isn't about making the PS2 useful for AI. It's a proof of concept that demonstrates three important things:
1. AI doesn't need expensive hardware to run. If a 10-million parameter model can stream from a CD-ROM on 32 MB of RAM, imagine what's possible on a $50 Raspberry Pi or a 10-year-old phone.
2. Quantization keeps getting better. The project uses custom 4-bit and 8-bit compression (a technique that shrinks AI models by reducing the precision of their numbers) to make models small enough to stream. This is the same technology making AI run on phones today.
3. Creative engineering beats raw compute. The streaming architecture — loading one matrix at a time, using block sharing to minimize disc reads — is genuinely clever systems engineering.
Try it yourself
If you happen to have a PlayStation 2 (or a PS2 emulator like PCSX2), the entire project is open source on GitHub. You'll need to convert a HuggingFace model to the custom PSNT format using the included Python tools, then burn it to a disc or load it via USB.
# Clone the repo
git clone https://github.com/xaskasdf/ps2-llm.git
# Convert a model to PS2 format
python convert_model.py --model brandon-tiny-10m-instruct --quant q8Controls are wonderfully console-appropriate: press X to edit your prompt, SQUARE to regenerate the response.
The project joins a growing wave of experiments pushing AI onto improbable hardware — from Microsoft's BitNet running 100B models on a single CPU to CompactifAI shrinking models 95% to run on phones. The message is clear: AI is becoming a technology that runs everywhere, not just in data centers.
Related Content — Get Started with Easy Claude Code | Free Learning Guides | More AI News
Stay updated on AI news
Simple explanations of the latest AI developments